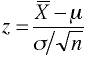
Tests of Significance
Hotelling's T2
Single Sample Problems
Known Covariance Matrix Σ
Univariate
Multivariate
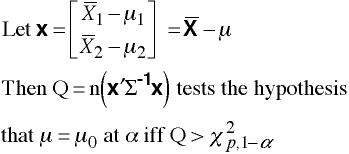
Single-Sample with known Population Covariance Matrix
Stata Matrix Program
scalar n = 25 matrix mu = (17 \ 10) matrix xbar = (15.4 \ 9.9) matrix sigma = (16, 8 \ 8, 9) matrix x = xbar - mu matrix list mu matrix list xbar matrix list x matrix list sigma matrix Q = n * x'*syminv(sigma)*x display "Q = " el(Q,1,1)
Discuss
Covariance Matrix Unknown
Univariate
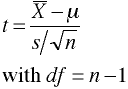
Multivariate
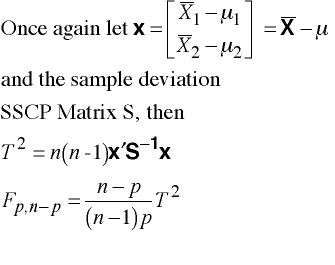
Single-Sample with Unknown Population Covariance Matrix
Stata Matrix Program
scalar n = 22 matrix mu = (31 \ 32) matrix xbar = (32.6 \ 33.5) matrix s = (47.25, 42.02 \ 42.02, 111.09) scalar rows = rowsof(s) matrix x = xbar - mu matrix list mu matrix list xbar matrix list x matrix list s scalar c = n * (n - 1) matrix T2 = c * x'*syminv(s)*x display "T-squared = " el(T2,1,1) scalar df2 = n - rows scalar c = df2/((n - 1)*rows) matrix F = c * T2 display "F = " el(F,1,1) display "p = " rows " df2 = " df2Stata Example
To do the single-sample Hotelling's T2 in Stata, we first need to create variables that contain the hypothesized population means and then create difference variables. In this example, the hypothesized population means are the same same for both read and write.
use http://www.philender.com/courses/data/hsb2, clear
summarize read write
Variable | Obs Mean Std. Dev. Min Max
-------------+--------------------------------------------------------
read | 200 52.23 10.25294 28 76
write | 200 52.775 9.478586 31 6
/* test against a population mean value vector [50, 50] */
generate mean=50
generate dif1 = read-mean
generate dif2 = write-mean
hotel dif1 dif2
Variable | Obs Mean Std. Dev. Min Max
-------------+--------------------------------------------------------
dif1 | 200 2.23 10.25294 -22 26
dif2 | 200 2.775 9.478586 -19 17
1-group Hotelling's T-squared = 17.710866
F test statistic: ((200-2)/(200-1)(2)) x 17.710866 = 8.8109335
H0: Vector of means is equal to a vector of zeros
F(2,198) = 8.8109
Prob > F(2,198) = 0.0002
Dependent t
Univariate
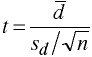
with n-1 degrees of freedom.
Multivariate
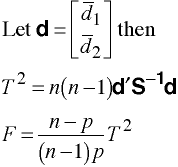
with df= p & n-p
Dependent Example
X1 D 25 22 28 35 37 48 49 54 65 57 H 26 22 29 39 34 51 42 54 77 68 X2 D 2.0 2.0 2.7 2.7 3.0 1.7 2.0 2.0 2.7 1.0 H 2.3 1.0 3.7 3.3 10.0 4.3 4.7 7.0 3.3 1.7 The difference scores (H -D) for each pair of the two variables are: D 1 0 1 4 -3 3 -7 0 12 11 0.3 -1.0 1.0 0.6 7.0 2.6 2.7 5.0 0.6 0.7 Yielding dbar' = [2.2 1.95] and S = [301.6 -56.4, -56.4 53.25]
Stata Marix Program
scalar n = 10 scalar p = 2 matrix dbar = (2.2 \ 1.95) matrix list dbar matrix s = (301.6, -56.4 \ -56.4, 53.325) matrix list s matrix t2 = n*(n-1)*dbar'*(syminv(s))*dbar display "T-squared = " el(t2,1,1) scalar df2 = n-p matrix f = df2/((n-1)*p)*t2 display "F = " el(f,1,1) display "p = " p " df2 = " df2Stata Example
To do the dependent-sample Hotelling's T2 in Stata, we once again need to create difference variables. In this example, x1 is the difference betweeen the deaf and the hearing for grip and x2 is the difference for balance.
input x1d x1h x2d x2h
25 26 2 2.3
22 22 2 1
28 29 2.7 3.7
35 39 2.7 3.3
37 34 3 10
48 51 1.7 4.3
49 42 2 4.7
54 54 2 7
65 77 2.7 3.3
57 68 1 1.7
end
gen x1 = x1d-x1h
gen x2 = x2d-x2h
hotel x1 x2
Variable | Obs Mean Std. Dev. Min Max
-------------+--------------------------------------------------------
x1 | 10 -2.2 5.788878 -12 7
x2 | 10 -1.95 2.434132 -7 1
1-group Hotelling's T-squared = 13.176046
F test statistic: ((10-2)/(10-1)(2)) x 13.176046 = 5.8560205
H0: Vector of means is equal to a vector of zeros
F(2,8) = 5.8560
Prob > F(2,8) = 0.0271
Univariate
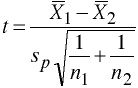
with df = n1 + n2 -2
Rewriting t yields
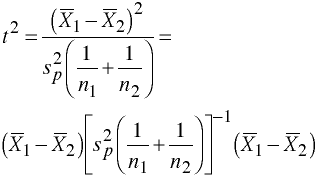
Multivariate
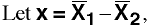
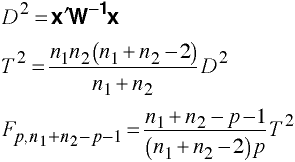
Two-Group Example
Stata Matrix Program
scalar n1 = 5 scalar n2 = 5 matrix xb1 = (14.2 \ 9.0) matrix xb2 = (12.8 \ 16.2) matrix x = xb1 - xb2 matrix w = (567.6, 215.2 \ 215.2, 96.8) scalar p = rowsof(w) scalar c = (n1 * n2 * (n1 + n2 -2))/(n1 + n2) matrix T2 = c * x'*syminv(w)*x display "T-squared = " el(T2,1,1) scalar df2 = n1 + n2 - p - 1 scalar c = df2/((n1 + n2 - 2)*p) matrix F = c * T2 display "F = " el(F,1,1) display "degrees of freedom = " p " and " df2Stata Example
input y1 y2 y3 group
1.21 .61 .70 1
.92 .43 .71 1
.80 .35 .71 1
.85 .48 .68 1
.98 .42 .71 1
1.15 .52 .72 1
1.10 .50 .75 1
1.02 .53 .70 1
1.18 .45 .70 1
1.09 .40 .69 1
1.40 .50 .71 2
1.17 .39 .69 2
1.23 .44 .70 2
1.19 .37 .72 2
1.38 .42 .71 2
1.17 .45 .70 2
1.31 .41 .70 2
1.30 .47 .67 2
1.22 .29 .68 2
1.00 .30 .70 2
1.12 .27 .72 2
1.09 .35 .73 2
end
tabstat y1 y2 y3, by(group) stat(mean sd)
Summary statistics: mean, sd
by categories of: group
group | y1 y2 y3
---------+------------------------------
1 | 1.03 .469 .707
| .1405544 .0748999 .0188856
---------+------------------------------
2 | 1.215 .3883333 .7025
| .1181293 .0740802 .0171226
---------+------------------------------
Total | 1.130909 .425 .7045455
| .1570535 .0834808 .0176547
----------------------------------------
hotel y1 y2 y3, by(group)
-> group= 1
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
y1 | 10 1.03 .1405544 .8 1.21
y2 | 10 .469 .0748999 .35 .61
y3 | 10 .707 .0188856 .68 .75
-> group= 2
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
y1 | 12 1.215 .1181293 1 1.4
y2 | 12 .3883333 .0740802 .27 .5
y3 | 12 .7025 .0171226 .67 .73
2-group Hotelling's T-squared = 52.342102
F test statistic: ((22-3-1)/(22-2)(3)) x 52.342102 = 15.702631
H0: Vectors of means are equal for the two groups
F(3,18) = 15.7026
Pr > F(3,18) = 0.0000
/* using manova */
manova y1 y2 y3 = group
Number of obs = 22
W = Wilks' lambda L = Lawley-Hotelling trace
P = Pillai's trace R = Roy's largest root
Source | Statistic df F(df1, df2) = F Prob>F
-----------+--------------------------------------------------
group | W 0.2765 1 3.0 18.0 15.70 0.0000 e
| P 0.7235 3.0 18.0 15.70 0.0000 e
| L 2.6171 3.0 18.0 15.70 0.0000 e
| R 2.6171 3.0 18.0 15.70 0.0000 e
|--------------------------------------------------
Residual | 20
-----------+--------------------------------------------------
Total | 21
--------------------------------------------------------------
e = exact, a = approximate, u = upper bound on F
/* using mvreg */
xi: mvreg y1 y2 y3 = i.group
i.group _Igroup_1-2 (naturally coded; _Igroup_1 omitted)
Equation Obs Parms RMSE "R-sq" F P
----------------------------------------------------------------------
y1 22 2 .1287051 0.3604 11.26965 0.0031
y2 22 2 .0744502 0.2425 6.403464 0.0199
y3 22 2 .0179374 0.0169 .3432919 0.5645
------------------------------------------------------------------------------
| Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
y1 |
_Igroup_2 | .185 .0551082 3.36 0.003 .0700462 .2999537
_cons | 1.03 .0407001 25.31 0.000 .945101 1.114899
-------------+----------------------------------------------------------------
y2 |
_Igroup_2 | -.0806667 .0318777 -2.53 0.020 -.1471623 -.014171
_cons | .469 .0235432 19.92 0.000 .4198897 .5181103
-------------+----------------------------------------------------------------
y3 |
_Igroup_2 | -.0045 .0076803 -0.59 0.564 -.0205209 .0115209
_cons | .707 .0056723 124.64 0.000 .6951678 .7188322
------------------------------------------------------------------------------
mvtest _Igroup_2 /* findit mvtest */
MULTIVARIATE TESTS OF SIGNIFICANCE
Multivariate Test Criteria and Exact F Statistics for
the Hypothesis of no Overall "_Igroup_2" Effect(s)
S=1 M=.5 N=8
Test Value F Num DF Den DF Pr > F
Wilks' Lambda 0.27646418 15.7026 3 18.0000 0.0000
Pillai's Trace 0.72353582 15.7026 3 18.0000 0.0000
Hotelling-Lawley Trace 2.61710509 15.7026 3 18.0000 0.0000
regress group y1 y2 y3
Source | SS df MS Number of obs = 22
-------------+------------------------------ F( 3, 18) = 15.70
Model | 3.94655901 3 1.31551967 Prob > F = 0.0000
Residual | 1.50798645 18 .083777025 R-squared = 0.7235
-------------+------------------------------ Adj R-squared = 0.6775
Total | 5.45454545 21 .25974026 Root MSE = .28944
------------------------------------------------------------------------------
group | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
y1 | 2.246938 .4087437 5.50 0.000 1.388199 3.105677
y2 | -3.691243 .766785 -4.81 0.000 -5.302199 -2.080288
y3 | -2.242679 3.588098 -0.63 0.540 -9.780994 5.295636
_cons | 2.153219 2.612195 0.82 0.421 -3.334799 7.641237
------------------------------------------------------------------------------
/* using canonical correlation analysis */
canon (y1 y2 y3)(group)
Linear combinations for canonical correlations Number of obs = 22
------------------------------------------------------------------------------
| Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
u1 |
y1 | 5.183122 .9428692 5.50 0.000 3.222318 7.143926
y2 | -8.514772 1.768781 -4.81 0.000 -12.19315 -4.836391
y3 | -5.173297 8.276842 -0.63 0.539 -22.38593 12.03934
-------------+----------------------------------------------------------------
v1 |
group | 1.962142 .2712094 7.23 0.000 1.398131 2.526153
------------------------------------------------------------------------------
(Standard errors estimated conditionally)
Canonical correlations:
0.8506
----------------------------------------------------------------------------
Tests of significance of all canonical correlations
Statistic df1 df2 F Prob>F
Wilks' lambda .276464 3 18 15.7026 0.0000 e
Pillai's trace .723536 3 18 15.7026 0.0000 e
Lawley-Hotelling trace 2.61711 3 18 15.7026 0.0000 e
Roy's largest root 2.61711 3 18 15.7026 0.0000 e
----------------------------------------------------------------------------
e = exact, a = approximate, u = upper bound on F
/* now the other way around */
canon (group)(y1 y2 y3)
Linear combinations for canonical correlations Number of obs = 22
------------------------------------------------------------------------------
| Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
u1 |
group | 1.962142 .2712094 7.23 0.000 1.398131 2.526153
-------------+----------------------------------------------------------------
v1 |
y1 | 5.183122 .9428692 5.50 0.000 3.222318 7.143926
y2 | -8.514772 1.768781 -4.81 0.000 -12.19315 -4.836391
y3 | -5.173297 8.276842 -0.63 0.539 -22.38593 12.03934
------------------------------------------------------------------------------
(Standard errors estimated conditionally)
Canonical correlations:
0.8506
----------------------------------------------------------------------------
Tests of significance of all canonical correlations
Statistic df1 df2 F Prob>F
Wilks' lambda .276464 3 18 15.7026 0.0000 e
Pillai's trace .723536 3 18 15.7026 0.0000 e
Lawley-Hotelling trace 2.61711 3 18 15.7026 0.0000 e
Roy's largest root 2.61711 3 18 15.7026 0.0000 e
----------------------------------------------------------------------------
e = exact, a = approximate, u = upper bound on F
/* using linear discriminant analysis in Stata 10*/
candisc y1 y2 y3, group(group)
Canonical linear discriminant analysis
| | Like-
| Canon. Eigen- Variance | lihood
Fcn | Corr. value Prop. Cumul. | Ratio F df1 df2 Prob>F
----+---------------------------------+------------------------------------
1 | 0.8506 2.61711 1.0000 1.0000 | 0.2765 15.703 3 18 0.0000 e
---------------------------------------------------------------------------
Ho: this and smaller canon. corr. are zero; e = exact F
[ ...output omitted... ]
Multivariate Course Page
Phil Ender, 17jul07, 18oct05, 28feb05, 6feb05, 29Jan98