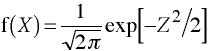
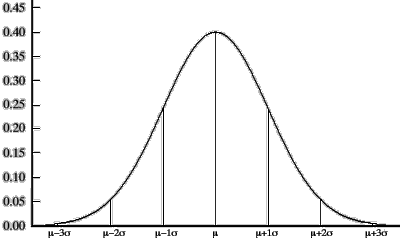
Univariate Standard Normal Distribution
Generalized Univariate Normal Distribution
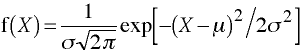
Bivariate Normal Distribution
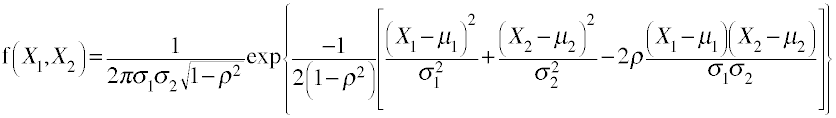
If X1 & X2 are uncorrelated
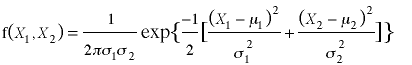
Matrix Genearalization of Bivariate Normal Distribution
Population Centroid
Also known as the population mean value vector.
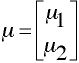
Deviation Score Vector
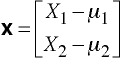
Covariance Matrix
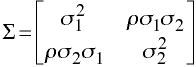
Quadratic Form
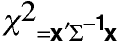
It is distributed as a chi-square
variate with 2 degrees of freedom.
Bivariate Normal Distribution
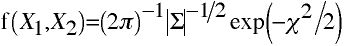
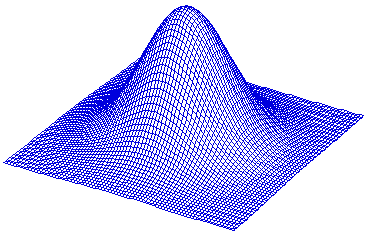
Example 1: ρ = 0.00
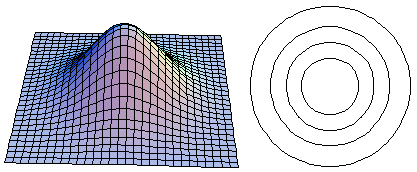
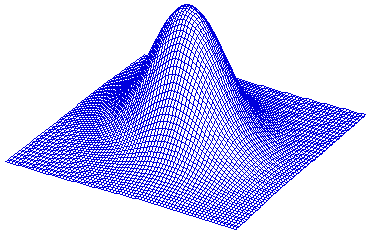
Example 2: ρ = 0.3
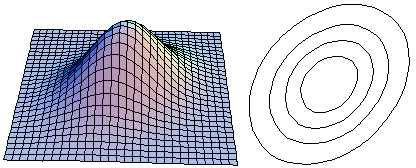
Example 3: ρ = 0.6
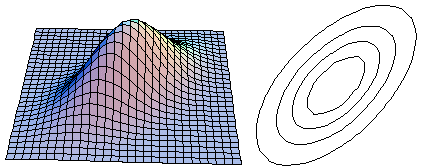
Example 4: ρ = 0.9
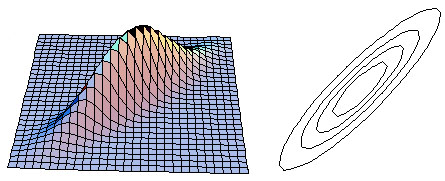
SAS Generated Examples
Example 1: ρ = 0.0
Example 2: ρ = 0.3
Example 3: ρ = 0.6
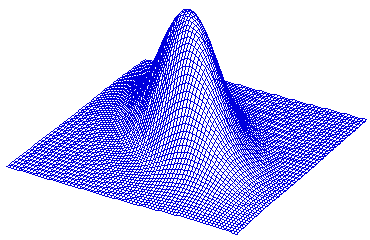
Example 4: ρ = 0.9
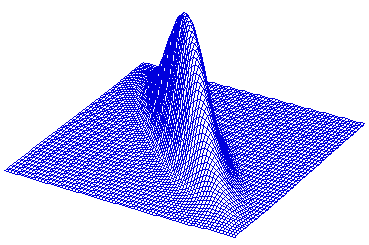
Multivariate Normal Distribution
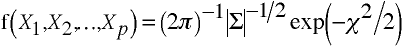
Theorem 1
Given a p-variate normal population N(μ, Σ) with density function
f(X1,X2, ... , Xp) = (2π)-1|Σ|-1/2 exp(-χ2/2) = 1/(2π · sqrt(|Σ|)) exp(-χ2/2)
the quantity χ2 = X´Σ-1X in the exponent is a chi-square variate with p degrees of freedom.
Regions Enclosing Specified Percentages of a Multivariate Normal Population

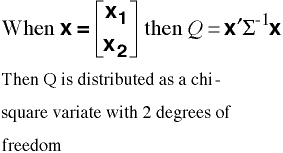
Example
The ellipse below represents a 90% isodensity ellipse from the quadratic form:
x'Σ-1x, where x' = [X1-15, X2-20]
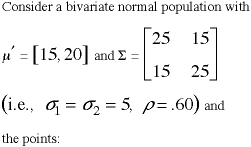
| Point | Q-value |
| P1(8,5) | 2.563 |
| P2(-5,-5) | 1.250 |
| P3(4,-5.565) | 4.605 |
| P4(-3,8) | 6.363 |
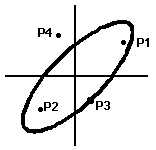
Points with Q values less than or equal to 4.605 (df = 2) fall inside or on the 90% isodensity ellipse. Those with Q values less than or equal to 5.991 fall inside or on the 95% isodensity ellipse.
Sampling Distribution of Sample Centroids
Some texts refer to sample centroids and sample mean value vectors.

Theorem 2
This is the multivariate extension of the central limit theorem.
Sample centroids (sample mean value vectors), 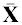 , based
on independent random samples of size n from a population N(μ, Σ)
have a sampling
distribution N(μ, (1/n)·Σ)
, based
on independent random samples of size n from a population N(μ, Σ)
have a sampling
distribution N(μ, (1/n)·Σ)
This parallels the univariate case in which sample means, 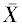 , based on independent random
samples of size n from a population N(μ, σ2) have a sampling
distribution N(μ, (1/n)·σ2)
, based on independent random
samples of size n from a population N(μ, σ2) have a sampling
distribution N(μ, (1/n)·σ2)
Multivariate Normal Outliers
If we are dealing with univariate distributions there are many tools we can use to identify outliers. One of the easier tools is a simple boxplot.
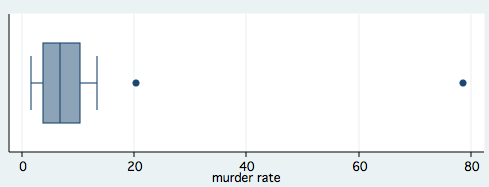
The situation is not as easy for multivariate distributions. Classical outlier detection methods are powerful when the data contain only one outlier but get bogged down when more than one outlier are present. A method developed by Hadi attempts to overcome these concerns by using a measure of distance from an observation to a cluster of points. A base cluster of r points is selected and then the cluster is continually redefined by taking the r+1 points "closest" as a new cluster. The procedure continues until some stopping rule is encountered.
We will demonstrate the use of the Hadi method using the hadimvo procedure found in a earlier version of Stata. Note: The hadimvo command can still be used in the lastest versions of Stata but it is no longer documented in the printed manuals.
use http://www.gseis.ucla.edu/courses/data/crime, clear
summarize crime murder pctmetro pcths poverty
Variable | Obs Mean Std. Dev. Min Max
-------------+--------------------------------------------------------
crime | 51 612.8431 441.1003 82 2922
murder | 51 8.727451 10.71758 1.6 78.5
pctmetro | 51 67.3902 21.95713 24 100
pcths | 51 76.22353 5.592087 64.3 86.6
poverty | 51 14.25882 4.584242 8 26.4
hadimvo crime murder pctmetro pcths poverty, gen(out)
Beginning number of observations: 51
Initially accepted: 6
Expand to (n+k+1)/2: 28
Expand, p = .05: 50
Outliers remaining: 1
list if out, clean
sid state crime murder pctmetro pctwhite pcths poverty single out
51. 51 dc 2922 78.5 100 31.8 73.1 26.4 22.1 1
summarize crime murder pctmetro pcths poverty if ~out
Variable | Obs Mean Std. Dev. Min Max
-------------+--------------------------------------------------------
crime | 50 566.66 295.8773 82 1206
murder | 50 7.332 3.984021 1.6 20.3
pctmetro | 50 66.738 21.6753 24 100
pcths | 50 76.286 5.630855 64.3 86.6
poverty | 50 14.016 4.286684 8 26.4
use http://www.gseis.ucla.edu/courses/data/gseis, clear
drop if missing(grea) | missing(greq) | missing(grev)
(82 observations deleted)
hadimvo grea greq grev, gen(out)
Beginning number of observations: 747
Initially accepted: 4
Expand to (n+k+1)/2: 375
Expand, p = .05: 745
Outliers remaining: 2
list grea greq grev if out, clean
grea greq grev
746. 250 720 520
747. 200 670 600
Of course, once identified, one must decide what to do with the outliers. Simple deletion of
outliers is usually not the best solution. Outliers may be providing important information
on low probability occurances. Having many outliers may be an indicator that the data do
not come from a multivariate normal distribution.
Multivariate Course Page
Phil Ender, 21Sep05, 29Jan98