F-ratio Using R2
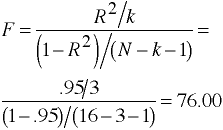
An example using hsbdemo
Let's analyze the hsbdemo data for the variable program type (prog) using write as the dependent variable. We will dummy code prog using the tabulate command with the generate option to create the dummy variables for us automatically.
use http://www.gseis.ucla.edu/courses/data/hsbdemo, clear
tab prog, gen(prog)
type of |
program | Freq. Percent Cum.
------------+-----------------------------------
general | 45 22.50 22.50
academic | 105 52.50 75.00
vocation | 50 25.00 100.00
------------+-----------------------------------
Total | 200 100.00ed)
regress write prog2 prog3
Source | SS df MS Number of obs = 200
---------+------------------------------ F( 2, 197) = 21.27
Model | 3175.69786 2 1587.84893 Prob > F = 0.0000
Residual | 14703.1771 197 74.635417 R-squared = 0.1776
---------+------------------------------ Adj R-squared = 0.1693
Total | 17878.875 199 89.843593 Root MSE = 8.6392
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+--------------------------------------------------------------------
prog2 | 4.92381 1.539279 3.199 0.002 1.888231 7.959388
prog3 | -4.573333 1.775183 -2.576 0.011 -8.074134 -1.072533
_cons | 51.33333 1.287853 39.860 0.000 48.79359 53.87308
------------------------------------------------------------------------------
test prog2 prog3
( 1) prog2 = 0.0
( 2) prog3 = 0.0
F( 2, 197) = 21.27
Prob > F = 0.0000It is also possible to have Stata perform dummy coding on-the-fly using factor variables.
regress write i.prog
Source | SS df MS Number of obs = 200
-------------+------------------------------ F( 2, 197) = 21.27
Model | 3175.69786 2 1587.84893 Prob > F = 0.0000
Residual | 14703.1771 197 74.635417 R-squared = 0.1776
-------------+------------------------------ Adj R-squared = 0.1693
Total | 17878.875 199 89.843593 Root MSE = 8.6392
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
prog |
2 | 4.92381 1.539279 3.20 0.002 1.888231 7.959388
3 | -4.573333 1.775183 -2.58 0.011 -8.074134 -1.072533
|
_cons | 51.33333 1.287853 39.86 0.000 48.79359 53.87308
------------------------------------------------------------------------------
testparm i.prog
( 1) 2.prog = 0
( 2) 3.prog = 0
F( 2, 197) = 21.27
Prob > F = 0.0000Effect coding using manual coding
In this example group one is the reference group, i.e., the group that would be coded -1.
replace prog2 = -1 if prog==1
replace prog3 = -1 if prog==1
regress write prog2 prog3
Source | SS df MS Number of obs = 200
-------------+------------------------------ F( 2, 197) = 21.27
Model | 3175.69786 2 1587.84893 Prob > F = 0.0000
Residual | 14703.1771 197 74.635417 R-squared = 0.1776
-------------+------------------------------ Adj R-squared = 0.1693
Total | 17878.875 199 89.843593 Root MSE = 8.6392
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
prog2 | 4.806984 .8161241 5.89 0.000 3.197523 6.416445
prog3 | -4.690159 .9626475 -4.87 0.000 -6.588576 -2.791742
_cons | 51.45016 .6550731 78.54 0.000 50.1583 52.74201
------------------------------------------------------------------------------
The ANOVA AlternativeMany people picture anova software as being good only for classical experimental designs with categorical variables. However, the Stata anova command is actually regression in disguise. Consider the following regression that has both categorical and continuous variables and their interactions.
use http://www.philender/courses/data/hsbdemo, clear
tabulate prog, gen(prog)
type of |
program | Freq. Percent Cum.
------------+-----------------------------------
general | 45 22.50 22.50
academic | 105 52.50 75.00
vocation | 50 25.00 100.00
------------+-----------------------------------
Total | 200 100.00
regress write i.female i.prog##c.read i.prog##c.math
Source | SS df MS Number of obs = 200
-------------+------------------------------ F( 9, 190) = 25.80
Model | 9833.77329 9 1092.64148 Prob > F = 0.0000
Residual | 8045.10171 190 42.3426406 R-squared = 0.5500
-------------+------------------------------ Adj R-squared = 0.5287
Total | 17878.875 199 89.843593 Root MSE = 6.5071
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.female | 5.706612 .9390611 6.08 0.000 3.854288 7.558937
|
prog |
2 | 5.872569 8.496026 0.69 0.490 -10.88608 22.63122
3 | -3.126916 9.509236 -0.33 0.743 -21.88415 15.63032
|
read | .5184569 .1172236 4.42 0.000 .2872301 .7496837
|
prog#c.read |
2 | -.3111253 .1493291 -2.08 0.039 -.6056813 -.0165694
3 | -.2499231 .1666047 -1.50 0.135 -.5785557 .0787094
|
math | .2072995 .1436855 1.44 0.151 -.0761243 .4907233
|
prog#c.math |
2 | .2062863 .1759469 1.17 0.242 -.140774 .5533465
3 | .2725577 .1950709 1.40 0.164 -.1122251 .6573405
|
_cons | 12.12411 7.35309 1.65 0.101 -2.380063 26.62829
------------------------------------------------------------------------------
testparm prog#c.math
( 1) 2.prog#c.math = 0
( 2) 3.prog#c.math = 0
F( 2, 190) = 1.06
Prob > F = 0.3482
test prog#c.read
( 1) 2.prog#c.read = 0
( 2) 3.prog#c.read = 0
F( 2, 190) = 2.25
Prob > F = 0.1079
test 1.female
( 1) 1.female = 0
F( 1, 190) = 36.93
Prob > F = 0.0000Admittedly, that wasn't a very interesting model but it did illustrate one way to put together all the pieces involved in model with categorical and interaction terms. Now, let's look at exactly the same model using the anova command.
anova write i.female i.prog##c.read i.prog##c.math
Number of obs = 200 R-squared = 0.5500
Root MSE = 6.50712 Adj R-squared = 0.5287
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 9833.77329 9 1092.64148 25.80 0.0000
|
female | 1563.67667 1 1563.67667 36.93 0.0000
prog | 66.1182428 2 33.0591214 0.78 0.4595
read | 1170.32031 1 1170.32031 27.64 0.0000
prog#read | 190.783714 2 95.3918572 2.25 0.1079
math | 1066.81222 1 1066.81222 25.19 0.0000
prog#math | 89.8348393 2 44.9174197 1.06 0.3482
|
Residual | 8045.10171 190 42.3426406
-----------+----------------------------------------------------
Total | 17878.875 199 89.843593
regress
Source | SS df MS Number of obs = 200
-------------+------------------------------ F( 9, 190) = 25.80
Model | 9833.77329 9 1092.64148 Prob > F = 0.0000
Residual | 8045.10171 190 42.3426406 R-squared = 0.5500
-------------+------------------------------ Adj R-squared = 0.5287
Total | 17878.875 199 89.843593 Root MSE = 6.5071
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.female | 5.706612 .9390611 6.08 0.000 3.854288 7.558937
|
prog |
2 | 5.872569 8.496026 0.69 0.490 -10.88608 22.63122
3 | -3.126916 9.509236 -0.33 0.743 -21.88415 15.63032
|
read | .5184569 .1172236 4.42 0.000 .2872301 .7496837
|
prog#c.read |
2 | -.3111253 .1493291 -2.08 0.039 -.6056813 -.0165694
3 | -.2499231 .1666047 -1.50 0.135 -.5785557 .0787094
|
math | .2072995 .1436855 1.44 0.151 -.0761243 .4907233
|
prog#c.math |
2 | .2062863 .1759469 1.17 0.242 -.140774 .5533465
3 | .2725577 .1950709 1.40 0.164 -.1122251 .6573405
|
_cons | 12.12411 7.35309 1.65 0.101 -2.380063 26.62829
------------------------------------------------------------------------------
The results are the same as the regression analysis however the set-up of the model to be
tested was a little more straight forward. Let's try one more.ANOVA Exampe 2
use http://www.philender.com/courses/data/htwt, clear
anova weight i.female##c.height
Number of obs = 1000 R-squared = 0.2795
Root MSE = 8.20887 Adj R-squared = 0.2773
Source | Partial SS df MS F Prob > F
--------------+----------------------------------------------------
Model | 26034.4351 3 8678.14505 128.78 0.0000
|
female | 587.074483 1 587.074483 8.71 0.0032
height | 19197.3548 1 19197.3548 284.89 0.0000
female#height | 547.82512 1 547.82512 8.13 0.0044
|
Residual | 67115.9985 996 67.3855406
--------------+----------------------------------------------------
Total | 93150.4336 999 93.2436773
regress
Source | SS df MS Number of obs = 1000
-------------+------------------------------ F( 3, 996) = 128.78
Model | 26034.4351 3 8678.14505 Prob > F = 0.0000
Residual | 67115.9985 996 67.3855406 R-squared = 0.2795
-------------+------------------------------ Adj R-squared = 0.2773
Total | 93150.4336 999 93.2436773 Root MSE = 8.2089
------------------------------------------------------------------------------
weight | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.female | 38.26321 12.96338 2.95 0.003 12.82455 63.70188
height | .7706638 .052059 14.80 0.000 .6685058 .8728217
|
female#|
c.height |
1 | -.2227448 .0781214 -2.85 0.004 -.3760463 -.0694434
|
_cons | -72.01376 8.892743 -8.10 0.000 -89.46442 -54.56309
------------------------------------------------------------------------------