
An alternative to logistic regression analysis is probit analysis. The term "probit' was coined in the 1930's by Chester Bliss and stands for probability unit. These two analyses, logit and probit, are very similar to one another. As discussed in the previous unit logit analysis is based on log odds while probit uses the cumulative normal probability distribution. Here is what a cumulative normal distribution looks like.
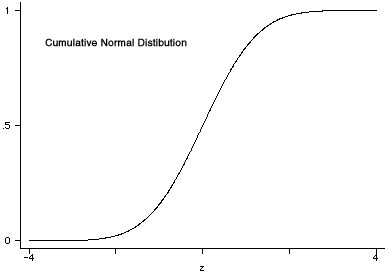
Since xb has a normal distribution, interpreting probit coefficients requires thinking in the Z (normal quantile) metric. The interpretation of a probit coefficient, b, is that a one-unit increase in the predictor leads to increasing the probit score by b standard deviations. Leaning to think and communicate in the Z metric takes practice and can be confusing to others. We will make use of a number of tools developed by Long and Freese to aid in the interpretation of the results.
The log-likelihood function for probit is
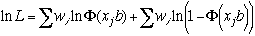
Currently, logic models are more popular than probit models due to two reasons; 1) the exponentiated logistic coefficients can be interpreted as odds ratios, and 2) there are more diagnostic tools available in logistic regression. Although, this last reason can be a chicken-egg issue, that is, there might be more diagnostic tools because it is being used more often.
We will demonstrate probit analysis using the same datasets that were used in the logistic regression analysis unit.
Example 1
set matsize 100
use http://www.gseis.ucla.edu/courses/data/honors
describe
Contains data from http://www.gseis.ucla.edu/courses/data/honors.dta
obs: 200
vars: 7 10 Feb 2001 16:27
size: 6,400 (99.8% of memory free)
-------------------------------------------------------------------------------
1. id float %9.0g
2. female float %9.0g fl
3. ses float %9.0g sl
4. lang float %9.0g language test score
5. math float %9.0g math score
6. science float %9.0g science score
7. honors float %9.0g
-------------------------------------------------------------------------------
summarize
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
id | 200 100.5 57.87918 1 200
female | 200 .545 .4992205 0 1
ses | 200 2.055 .7242914 1 3
lang | 200 52.23 10.25294 28 76
math | 200 52.645 9.368448 33 75
science | 200 51.85 9.900891 26 74
honors | 200 .265 .4424407 0 1
tab1 honors female
-> tabulation of honors
honors | Freq. Percent Cum.
------------+-----------------------------------
0 | 147 73.50 73.50
1 | 53 26.50 100.00
------------+-----------------------------------
Total | 200 100.00
-> tabulation of female
female | Freq. Percent Cum.
------------+-----------------------------------
male | 91 45.50 45.50
female | 109 54.50 100.00
------------+-----------------------------------
Total | 200 100.00
tabulate ses, gen(ses)
ses | Freq. Percent Cum.
------------+-----------------------------------
low | 47 23.50 23.50
middle | 95 47.50 71.00
high | 58 29.00 100.00
------------+-----------------------------------
Total | 200 100.00
probit honors lang math science female ses1 ses2
Probit estimates Number of obs = 200
LR chi2(6) = 90.64
Prob > chi2 = 0.0000
Log likelihood = -70.325874 Pseudo R2 = 0.3919
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
lang | .0374474 .0167054 2.242 0.025 .0047055 .0701893
math | .0660721 .0190501 3.468 0.001 .0287347 .1034096
science | .027691 .0182851 1.514 0.130 -.0081471 .0635291
female | .7738415 .2655413 2.914 0.004 .2533901 1.294293
ses1 | .0239919 .3458658 0.069 0.945 -.6538925 .7018763
ses2 | -.5750086 .2756539 -2.086 0.037 -1.11528 -.0347369
_cons | -8.021886 1.198495 -6.693 0.000 -10.37089 -5.672879
------------------------------------------------------------------------------
Just a note on the interpretation of the probit coefficients. The coefficient for math is
.07 to two decimal places. This indicates that a one-unit increase in the math score results
in a .07 standard deviation increase in the predicted probit index. And the coefficient
for female is interpreted to mean that the change from 0 to 1 increases the
predicted probit index by .77 standard deviations.
probit honors lang math female ses1 ses2
Probit estimates Number of obs = 200
LR chi2(5) = 88.28
Prob > chi2 = 0.0000
Log likelihood = -71.503442 Pseudo R2 = 0.3817
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
lang | .0439894 .0162434 2.708 0.007 .0121528 .0758259
math | .0760789 .018053 4.214 0.000 .0406958 .111462
female | .6752606 .2523046 2.676 0.007 .1807526 1.169769
ses1 | -.0275906 .3397904 -0.081 0.935 -.6935676 .6383864
ses2 | -.6179796 .2723557 -2.269 0.023 -1.151787 -.0841724
_cons | -7.334563 1.056422 -6.943 0.000 -9.405111 -5.264015
------------------------------------------------------------------------------
test ses1 ses2
( 1) ses1 = 0.0
( 2) ses2 = 0.0
chi2( 2) = 6.32
Prob > chi2 = 0.0425
for var lang math: generate fxX = female*X
probit honors lang math female ses1 ses2 fxlang fxmath
Probit estimates Number of obs = 200
LR chi2(7) = 89.08
Prob > chi2 = 0.0000
Log likelihood = -71.104283 Pseudo R2 = 0.3851
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
lang | .0325027 .0233381 1.393 0.164 -.0132391 .0782445
math | .0717692 .0254528 2.820 0.005 .0218825 .1216559
female | -.9346668 1.92794 -0.485 0.628 -4.713361 2.844027
ses1 | -.003803 .3424154 -0.011 0.991 -.6749249 .667319
ses2 | -.5965207 .2774592 -2.150 0.032 -1.140331 -.0527107
fxlang | .0203053 .0323945 0.627 0.531 -.0431868 .0837974
fxmath | .0081221 .0363954 0.223 0.823 -.0632115 .0794558
_cons | -6.427969 1.443015 -4.455 0.000 -9.256227 -3.599711
------------------------------------------------------------------------------
test fxlang fxmath
( 1) fxlang = 0.0
( 2) fxmath = 0.0
chi2( 2) = 0.81
Prob > chi2 = 0.6682
probit honors lang math female ses1 ses2
Probit estimates Number of obs = 200
LR chi2(5) = 88.28
Prob > chi2 = 0.0000
Log likelihood = -71.503442 Pseudo R2 = 0.3817
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
lang | .0439894 .0162434 2.708 0.007 .0121528 .0758259
math | .0760789 .018053 4.214 0.000 .0406958 .111462
female | .6752606 .2523046 2.676 0.007 .1807526 1.169769
ses1 | -.0275906 .3397904 -0.081 0.935 -.6935676 .6383864
ses2 | -.6179796 .2723557 -2.269 0.023 -1.151787 -.0841724
_cons | -7.334563 1.056422 -6.943 0.000 -9.405111 -5.264015
------------------------------------------------------------------------------
listcoef
probit (N=200): Unstandardized and Standardized Estimates
Observed SD: .4424407
Latent SD: 1.5392821
---------------------------------------------------------------------------
honors | b z P>|z| bStdX bStdY bStdXY SDofX
---------+-----------------------------------------------------------------
lang | 0.04399 2.708 0.007 0.4510 0.0286 0.2930 10.2529
math | 0.07608 4.214 0.000 0.7127 0.0494 0.4630 9.3684
female | 0.67526 2.676 0.007 0.3371 0.4387 0.2190 0.4992
ses1 | -0.02759 -0.081 0.935 -0.0117 -0.0179 -0.0076 0.4251
ses2 | -0.61798 -2.269 0.023 -0.3094 -0.4015 -0.2010 0.5006
---------------------------------------------------------------------------
prchange
probit: Changes in Predicted Probabilities for honors
min->max 0->1 -+1/2 -+sd/2 MargEfct
lang 0.5114 0.0001 0.0110 0.1130 0.0110
math 0.7624 0.0000 0.0191 0.1784 0.0191
female 0.1643 0.1643 0.1690 0.0845 0.1693
ses1 -0.0069 -0.0069 -0.0069 -0.0029 -0.0069
ses2 -0.1525 -0.1525 -0.1547 -0.0775 -0.1549
0 1
Pr(y|x) 0.8324 0.1676
lang math female ses1 ses2
x= 52.23 52.645 .545 .235 .475
sd(x)= 10.2529 9.36845 .49922 .425063 .500628
prtab math
probit: Predicted probabilities of positive outcome for honors
----------------------
math |
score | Prediction
----------+-----------
33 | 0.0070
35 | 0.0105
37 | 0.0156
38 | 0.0189
39 | 0.0226
40 | 0.0271
41 | 0.0322
42 | 0.0381
43 | 0.0448
44 | 0.0525
45 | 0.0611
46 | 0.0709
47 | 0.0818
48 | 0.0939
49 | 0.1073
50 | 0.1220
51 | 0.1381
52 | 0.1556
53 | 0.1744
54 | 0.1947
55 | 0.2163
56 | 0.2393
57 | 0.2635
58 | 0.2890
59 | 0.3155
60 | 0.3430
61 | 0.3714
62 | 0.4005
63 | 0.4301
64 | 0.4602
65 | 0.4905
66 | 0.5208
67 | 0.5510
68 | 0.5810
69 | 0.6104
70 | 0.6393
71 | 0.6673
72 | 0.6945
73 | 0.7206
75 | 0.7694
----------------------
lang math female ses1 ses2
x= 52.23 52.645 .545 .235 .475
prtab female
probit: Predicted probabilities of positive outcome for honors
----------------------
female | Prediction
----------+-----------
male | 0.0915
female | 0.2557
----------------------
lang math female ses1 ses2
x= 52.23 52.645 .545 .235 .475
prtab math female
probit: Predicted probabilities of positive outcome for honors
--------------------------
math | female
score | male female
----------+---------------
33 | 0.0024 0.0157
35 | 0.0037 0.0228
37 | 0.0058 0.0324
38 | 0.0072 0.0383
39 | 0.0089 0.0451
40 | 0.0109 0.0528
41 | 0.0133 0.0615
42 | 0.0161 0.0713
43 | 0.0194 0.0822
44 | 0.0233 0.0944
45 | 0.0278 0.1078
46 | 0.0331 0.1226
47 | 0.0391 0.1387
48 | 0.0460 0.1563
49 | 0.0538 0.1752
50 | 0.0626 0.1955
51 | 0.0726 0.2172
52 | 0.0837 0.2402
53 | 0.0960 0.2645
54 | 0.1096 0.2900
55 | 0.1245 0.3165
56 | 0.1408 0.3441
57 | 0.1585 0.3725
58 | 0.1776 0.4016
59 | 0.1981 0.4313
60 | 0.2200 0.4614
61 | 0.2431 0.4916
62 | 0.2676 0.5220
63 | 0.2932 0.5522
64 | 0.3199 0.5821
65 | 0.3476 0.6116
66 | 0.3761 0.6404
67 | 0.4053 0.6684
68 | 0.4350 0.6955
69 | 0.4651 0.7216
70 | 0.4954 0.7466
71 | 0.5257 0.7703
72 | 0.5559 0.7927
73 | 0.5858 0.8138
75 | 0.6439 0.8518
--------------------------
lang math female ses1 ses2
x= 52.23 52.645 .545 .235 .475Example 2
use http://www.gseis.ucla.edu/courses/data/api2000
describe
Contains data from api2000.dta
obs: 250
vars: 8 10 Feb 2001 14:58
size: 5,500 (99.9% of memory free)
-------------------------------------------------------------------------------
1. snum float %9.0g school number
2. api2000 int %6.0g
3. apigoal float %9.0g api>=800
4. meals byte %4.0f pct free meals
5. ell byte %4.0f english language learners
6. aved float %9.0g avg parent ed
7. full byte %4.0f pct full credential
8. emer byte %4.0f pct emer credential
-------------------------------------------------------------------------------
summarize
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
snum | 250 3165.612 1757.88 25 6186
api2000 | 250 669.92 137.6566 366 953
apigoal | 250 .2 .4008024 0 1
meals | 250 51.456 31.96321 0 100
ell | 250 26.352 25.60583 0 91
aved | 250 2.7422 .7750297 1 4.62
full | 250 87.684 13.57147 34 100
emer | 250 10.928 11.55512 0 63
tab apigoal
api>=800 | Freq. Percent Cum.
------------+-----------------------------------
0 | 200 80.00 80.00
1 | 50 20.00 100.00
------------+-----------------------------------
Total | 250 100.00
probit apigoal meals ell aved full
Probit estimates Number of obs = 250
LR chi2(4) = 151.08
Prob > chi2 = 0.0000
Log likelihood = -49.560174 Pseudo R2 = 0.6038
------------------------------------------------------------------------------
apigoal | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
meals | -.0426557 .0138114 -3.088 0.002 -.0697255 -.0155858
ell | .0025918 .0191673 0.135 0.892 -.0349755 .0401591
aved | 1.298466 .4034422 3.218 0.001 .5077338 2.089198
full | .0167719 .0216277 0.775 0.438 -.0256177 .0591614
_cons | -5.280958 2.613711 -2.020 0.043 -10.40374 -.1581779
------------------------------------------------------------------------------
Note: 11 failures and 0 successes completely determined.
probit apigoal meals aved
Probit estimates Number of obs = 250
LR chi2(2) = 150.47
Prob > chi2 = 0.0000
Log likelihood = -49.865959 Pseudo R2 = 0.6014
------------------------------------------------------------------------------
apigoal | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
meals | -.0431622 .0123059 -3.507 0.000 -.0672814 -.0190431
aved | 1.295674 .4003215 3.237 0.001 .5110583 2.08029
_cons | -3.656406 1.527895 -2.393 0.017 -6.651026 -.661787
------------------------------------------------------------------------------
Note: 1 failure and 0 successes completely determined
listcoef
probit (N=250): Unstandardized and Standardized Estimates
Observed SD: .40080241
Latent SD: 2.5147071
---------------------------------------------------------------------------
apigoal | b z P>|z| bStdX bStdY bStdXY SDofX
---------+-----------------------------------------------------------------
meals | -0.04316 -3.507 0.000 -1.3796 -0.0172 -0.5486 31.9632
aved | 1.29567 3.237 0.001 1.0042 0.5152 0.3993 0.7750
---------------------------------------------------------------------------
Example 3Example 3 involves the use of blocked data, i.e., each observation consists of the number of occurrances of a variable and the number of observations in the population. The syntax for bprobit looks like this,
bprobit pos_var pop_var [predictors] [if exp] [in range] [, probit_options]
use http://www.gseis.ucla.edu/courses/data/ashford
describe
Contains data from http://www.gseis.ucla.edu/courses/data/ashford.dta
obs: 9 from Ashford & Snowden - 1970
vars: 4 15 Feb 2001 22:58
size: 117 (100.0% of memory free)
-------------------------------------------------------------------------------
1. age byte %8.0g
2. pop int %8.0g population
3. cases int %8.0g cases of breathlessness
4. opro float %9.0g observed proportion
-------------------------------------------------------------------------------
bprobit cases pop age
Probit estimates Number of obs = 18282
LR chi2(1) = 2346.44
Prob > chi2 = 0.0000
Log likelihood = -5980.1529 Pseudo R2 = 0.1640
------------------------------------------------------------------------------
_outcome | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
age | .0550296 .0012746 43.173 0.000 .0525313 .0575278
_cons | -3.59412 .0619437 -58.022 0.000 -3.715528 -3.472713
------------------------------------------------------------------------------
predict pp, p
list age opro pp
age opro pp
1. 22 .0076844 .0085751
2. 27 .0178671 .0175016
3. 32 .034548 .0333883
4. 37 .0600072 .0596135
5. 42 .0980651 .0997673
6. 47 .1491851 .1567919
7. 52 .2492823 .2319065
8. 57 .3188571 .3236793
9. 62 .4207746 .4276788
Categorical Data Analysis Course
Phil Ender