
Note: Although we will be discussing and demonstrating model fit in the context of logistic regression, many of the concepts and indices apply to other categorical and non-normal models.
First Example
use http://www.philender.com/courses/data/honors, clear
logit honors lang math science female
Iteration 0: log likelihood = -115.64441
Iteration 1: log likelihood = -78.757483
Iteration 2: log likelihood = -74.10976
Iteration 3: log likelihood = -73.650266
Iteration 4: log likelihood = -73.642805
Iteration 5: log likelihood = -73.642803
Logit estimates Number of obs = 200
LR chi2(4) = 84.00
Prob > chi2 = 0.0000
Log likelihood = -73.642803 Pseudo R2 = 0.3632
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lang | .0631137 .0281071 2.25 0.025 .0080248 .1182026
math | .1113485 .0337503 3.30 0.001 .045199 .1774979
science | .0568872 .0326402 1.74 0.081 -.0070864 .1208607
female | 1.362197 .4605193 2.96 0.003 .4595958 2.264798
_cons | -14.57728 2.156767 -6.76 0.000 -18.80447 -10.3501
------------------------------------------------------------------------------Note: The pseudo-R2 given above is MacFadden's pseudo R2 which we will discuss later.
There are several tools built into Stata that deal with fit.
lfit
Logistic model for honors, goodness-of-fit test
number of covariate patterns = 199
Pearson chi2(194) = 164.86
Prob > chi2 = 0.9365Hosmer and Lemeshow suggest that when the number of covariate patterns is large relative to the number of observations that their index of fit is more appropriate.
lfit, group(10)
Logistic model for honors, goodness-of-fit test
(Table collapsed on quantiles of estimated probabilities)
number of observations = 200
number of groups = 10
Hosmer-Lemeshow chi2(8) = 8.25
Prob > chi2 = 0.4095Another way to look at fit is to examin the classification table.
lstat
Logistic model for honors
-------- True --------
Classified | D ~D | Total
-----------+--------------------------+-----------
+ | 31 10 | 41
- | 22 137 | 159
-----------+--------------------------+-----------
Total | 53 147 | 200
Classified + if predicted Pr(D) >= .5
True D defined as honors ~= 0
--------------------------------------------------
Sensitivity Pr( +| D) 58.49%
Specificity Pr( -|~D) 93.20%
Positive predictive value Pr( D| +) 75.61%
Negative predictive value Pr(~D| -) 86.16%
--------------------------------------------------
False + rate for true ~D Pr( +|~D) 6.80%
False - rate for true D Pr( -| D) 41.51%
False + rate for classified + Pr(~D| +) 24.39%
False - rate for classified - Pr( D| -) 13.84%
--------------------------------------------------
Correctly classified 84.00%
--------------------------------------------------Sensativity is proportion of the 1's that are correctly identified; 31/53 = .58490566. Specificity is the proportion of 0's correctly identified; 135/147 = .93197279. The proportion correctly classified, also known as the Count R2, is (31+137)/200 = .84.
Deviance
Deviance compares a given model to a fully saturated one. Deviance reflects error associated with the model even after the predictors are included in the model. It thus has to do with the significance of the unexplained variance in the response variable. One wants deviance to be not significant. That is, the significance should be worse than (greater than) .05. In many respects deviance in categorical models functions the way SSresid functions in OLS regression, that is, the smaller the deviance the better the model fits the data.
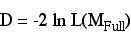
As discussed in an earlier unit the R2 in OLS regression can take on several different meanings, proportion of variance accounted for, squared correlation between fitted and predicted, and a transformation of the F-statistic. In categorical models there is no single index that fills all of these roles, instead there are a number of pseudo-R2 that have been developed to help in assessing fit.
McFadden's R2
This is also known as the likelihood-ratio index. It compares the likelihood for the intercept only model to the likelihood for the model with the predictors.
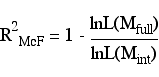
Adjusted McFadden's R2
The adjusted version of McFadden's R2 subtracts K, the number of parameters in the model. Thus, the Adjusted McFadden's R2 is to McFadden's R2 as the adjusted R2 is to R2 in OLS regression.
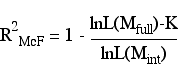
The maximum likelihood R2 expresses the model fit as a transformation of likelihood ratio chi-square in an analgous way to that of R2 in OLS regression which can be though of as a transformation of the F-statistic. The maximum likelihood R2 can reach a maximum of 1 - L(Mint)2/N.
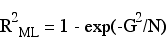
Because of the limitation on the maximum value for the maximum likelihood R2 Craig and Uhler proposed a relative index that can reach one.
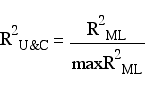
The McKelvey and Zavoina R2 is an attempt to measure model fit as the proportion of variance accounted for. In this case, we are attempting to explain the variance of the latent variable. The variance of the latent variable can be computed by y* = β'Var(x)β.
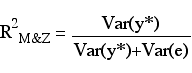
Efron's R2 is another model fit index based on proportion of variance accountef for.
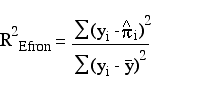
The count R2, as discussed above, is the proportion of correctly classified observations.
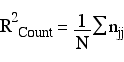
The count R2 can be misleading values under certain circumstances. In a binary model it is possible to correctly categorize at least 50% of the cases, without using information from the predictors, by choosing the outcome with the largest percentage. The count R2 needs to be adjusted by the largest row marginal total. In our example, the adjusted count R2 = ((31+137) - 147)/(200 - 147). Thus, the adjusted count R2 is the proportion of correct guesses beyond that by guessing the largest marginal.
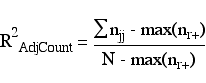
The pseudo-R2s are limited in that they can only be used to compare nested models. Model fit can also be based on measures of information. Akaike's information criterion (AIC) and the Bayesian information criterion (BIC) are two commonly used measures. One advantage to using information criterion measures is that they can be used to compare non-nested models.
For these information measures smaller is better.
AIC & AIC*n
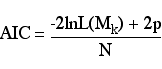
BIC & BIC'
The BIC is based upon the deviance while the BIC' uses the likelihood ratio chi-square. For BIC the term dfk is the degrees of freedom for the deviance and in the BIC' equation df'k is the number of predictors in the model.
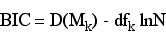
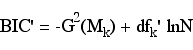
Interpreting BIC and BIC' Absolute Difference Evidence 0-2 Weak 2-6 Positive 7-10 Strong >10 Very StrongAnother Example
In the example below the likelihood ratios, deviances and pseudo-R2s can only be compared across nested models. The information indices can be used with non-nested models.
fitstat, saving(mod1)
Measures of Fit for logit of honors
Log-Lik Intercept Only: -115.644 Log-Lik Full Model: -73.643
D(195): 147.286 LR(4): 84.003
Prob > LR: 0.000
McFadden's R2: 0.363 McFadden's Adj R2: 0.320
Maximum Likelihood R2: 0.343 Cragg & Uhler's R2: 0.500
McKelvey and Zavoina's R2: 0.560 Efron's R2: 0.388
Variance of y*: 7.485 Variance of error: 3.290
Count R2: 0.840 Adj Count R2: 0.396
AIC: 0.786 AIC*n: 157.286
BIC: -885.886 BIC': -62.810
(Indices saved in matrix fs_mod1)
logit honors lang female
Iteration 0: log likelihood = -115.64441
Iteration 1: log likelihood = -87.936305
Iteration 2: log likelihood = -85.536982
Iteration 3: log likelihood = -85.443948
Iteration 4: log likelihood = -85.44372
Logit estimates Number of obs = 200
LR chi2(2) = 60.40
Prob > chi2 = 0.0000
Log likelihood = -85.44372 Pseudo R2 = 0.2612
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lang | .1443657 .0233337 6.19 0.000 .0986325 .1900989
female | 1.120926 .4081028 2.75 0.006 .321059 1.920793
_cons | -9.603365 1.426404 -6.73 0.000 -12.39906 -6.807665
------------------------------------------------------------------------------
fitstat, using(mod1)
Measures of Fit for logit of honors
Current Saved Difference
Model: logit logit
N: 200 200 0
Log-Lik Intercept Only: -115.644 -115.644 0.000
Log-Lik Full Model: -85.444 -73.643 -11.801
D: 170.887(197) 147.286(195) 23.602(2)
LR: 60.401(2) 84.003(4) 23.602(2)
Prob > LR: 0.000 0.000 0.000
McFadden's R2: 0.261 0.363 -0.102
McFadden's Adj R2: 0.235 0.320 -0.085
Maximum Likelihood R2: 0.261 0.343 -0.082
Cragg & Uhler's R2: 0.380 0.500 -0.120
McKelvey and Zavoina's R2: 0.423 0.560 -0.137
Efron's R2: 0.281 0.388 -0.108
Variance of y*: 5.706 7.485 -1.779
Variance of error: 3.290 3.290 0.000
Count R2: 0.785 0.840 -0.055
Adj Count R2: 0.189 0.396 -0.208
AIC: 0.884 0.786 0.098
AIC*n: 176.887 157.286 19.602
BIC: -872.881 -885.886 13.005
BIC': -49.805 -62.810 13.005
Difference of 13.005 in BIC' provides very strong support for saved model.
Note: p-value for difference in LR is only valid if models are nested.
Categorical Data Analysis Course
Phil Ender