
When the response variable is ordinal and has more than two levels, researchers have a choice between ordered logistic regression (ordered logit) and ordered probit models. A representation of the latent variable approach of an ordered variable might look like this.
-inf +inf
<-----+-----------+--------------------------+---------> y*
< 1 | 2 | 3 | 4 > y
τ1 τ2 τ3
Here is the rule we can use to relate the latent observations to our ordinal
response variable.
y = i if τi-1 <= y* < τi for i = 1..JThe structural model is
y* = xβ + εWe can now express the model in terms of probabilities.
P(y=i|x) = P(τi-1 < y* <= τi |x) P(y=i|x) = P(τi-1 < xβ + ε <= τi |x) P(y=i|x) = P(ε < τi - xβ |x) - P(ε <= τi-1 - xβ | x) P(y=i|x) = F(τi - xβ) - F(τi-1 - xβ)And now in terms of odds.
odds(y=k|x) = P(y <= k |x) / P(y > k |x) Ln(odds(y=k|x) = τk - xβThe log likelihood function for ordered logistic regression is

Let's begin our examination of ordered logistic regression using the honors dataset with the binary response variable honors composition (honors). We begin with an ordinary logistic regression.
use http://www.gseis.ucla.edu/courses/data/honors
logit honors female
Logit estimates Number of obs = 200
LR chi2(1) = 3.94
Prob > chi2 = 0.0473
Log likelihood = -113.6769 Pseudo R2 = 0.0170
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
female | .6513707 .3336752 1.95 0.051 -.0026207 1.305362
_cons | -1.400088 .2631619 -5.32 0.000 -1.915876 -.8842998
------------------------------------------------------------------------------
Next, we will run the ordered logistic regression command, ologit, for the same model.
ologit honors female
Ordered logit estimates Number of obs = 200
LR chi2(1) = 3.94
Prob > chi2 = 0.0473
Log likelihood = -113.6769 Pseudo R2 = 0.0170
------------------------------------------------------------------------------
honors | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
female | .6513707 .3336752 1.95 0.051 -.0026207 1.305362
-------------+----------------------------------------------------------------
_cut1 | 1.400088 .2631619 (Ancillary parameter)
------------------------------------------------------------------------------
We see that the values of the coefficients are the same, except that, the sign for _cut1
is reversed. We will explain shorty what _cut1 is
although it is already clear that it is related to the constant found in the logistic regression
models.Example 2
For our next example we will select ses as the response variable from the dataset hsb2. Ses has three ordered categories. Here are the frequencies for each of the categories.
use http://www.gseis.ucla.edu/courses/data/hsb2
tabulate ses
ses | Freq. Percent Cum.
------------+-----------------------------------
low | 47 23.50 23.50
middle | 95 47.50 71.00
high | 58 29.00 100.00
------------+-----------------------------------
Total | 200 100.00
We can also obtain much of the same information using the codebook command.codebook ses
ses --------------------------------------------------------------- (unlabeled)
type: numeric (float)
label: sl
range: [1,3] units: 1
unique values: 3 coded missing: 0 / 200
tabulation: Freq. Numeric Label
47 1 low
95 2 middle
58 3 high
For a predictor variable we will create a dummy variable academic which indicates
whether or not students are in an academic program. Here is the ordered logistic model predicting
ses using academic.generate academic=prog==2
ologit ses academic
Ordered logit estimates Number of obs = 200
LR chi2(1) = 11.83
Prob > chi2 = 0.0006
Log likelihood = -204.66504 Pseudo R2 = 0.0281
------------------------------------------------------------------------------
ses | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
academic | .9299309 .2745004 3.39 0.001 .39192 1.467942
-------------+----------------------------------------------------------------
_cut1 | -.7643189 .2042487 (Ancillary parameters)
_cut2 | 1.41461 .225507
------------------------------------------------------------------------------
The format of these results may seem confusing at first. What isn't clear from the output is that
logistic regression is a multiequation model. In this
example, there are two equations, each with the same logistic coefficients. This is known as
the proportional odds model. Other logistics regression models, which do not assume proportional
odds will have one equation, with their own constants and coefficients, for each of the k-1
equations.In our example, the results are formatted like a single equation model when, in fact, this are two equations in the model because there are three levels of ses. In ordered logistic regression, Stata sets the constant to zero and estimates the cut points for separating the various levels of the response variable. Other programs may parameterize the model differently by estimating the constant and setting the first cut point to zero.
SAS formats ordered logit models in a similar manner.
Data Set WORK.OLOG
Response Variable ses
Number of Response Levels 3
Number of Observations 200
Link Function Logit
Optimization Technique Fisher's scoring
Response Profile
Ordered Total
Value ses Frequency
1 1 47
2 2 95
3 3 58
Model Convergence Status
Convergence criterion (GCONV=1E-8) satisfied.
Score Test for the Proportional Odds Assumption
Chi-Square DF Pr > ChiSq
2.0046 1 0.1568
Model Fit Statistics
Intercept
Intercept and
Criterion Only Covariates
AIC 425.165 415.330
SC 431.762 425.225
-2 Log L 421.165 409.330
Testing Global Null Hypothesis: BETA=0
Test Chi-Square DF Pr > ChiSq
Likelihood Ratio 11.8350 1 0.0006
Score 11.6374 1 0.0006
Wald 11.4526 1 0.0007
Analysis of Maximum Likelihood Estimates
Standard
Parameter DF Estimate Error Chi-Square Pr > ChiSq
Intercept 1 -0.7643 0.2072 13.6032 0.0002
Intercept2 1 1.4146 0.2282 38.4156 <.0001
academic 1 -0.9299 0.2748 11.4526 0.0007
Odds Ratio Estimates
Point 95% Wald
Effect Estimate Confidence Limits
academic 0.395 0.230 0.676
Association of Predicted Probabilities and Observed Responses
Percent Concordant 35.8 Somers' D 0.203
Percent Discordant 15.6 Gamma 0.394
Percent Tied 48.6 Tau-a 0.129
Pairs 12701 c 0.601
With ordered logistic regression there are other possible estimation procedures that do not
involve the proportional odds assumption. Use the brant (findit brant --
one of the Long & Freese utilities) command
to test the proportional odds assumption.brant
Brant Test of Parallel Regression Assumption
Variable | chi2 p>chi2 df
-------------+--------------------------
All | 1.98 0.160 1
-------------+--------------------------
academic | 1.98 0.160 1
----------------------------------------
A significant test statistic provides evidence that the parallel
regression assumption has been violated.
These results suggest that the proportional odds approach is reasonable. If the test of
proportionality had been significant we could have tried the gologit program by Vincent
Kang Fu from UCLA [now at the University of Utah] (findit gologit).
gologit which stands for generalized ordered logit does not assume proportional odds,
let's try it just for "fun."gologit ses academic
Generalized Ordered Logit Estimates Number of obs = 200
Model chi2(2) = 13.83
Prob > chi2 = 0.0010
Log Likelihood = -203.6670799 Pseudo R2 = 0.0328
------------------------------------------------------------------------------
ses | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
mleq1 |
academic | .6374203 .3389678 1.88 0.060 -.0269444 1.301785
_cons | .8724882 .2250326 3.88 0.000 .4314324 1.313544
-------------+----------------------------------------------------------------
mleq2 |
academic | 1.191394 .3388816 3.52 0.000 .5271982 1.85559
_cons | -1.596859 .27415 -5.82 0.000 -2.134183 -1.059535
------------------------------------------------------------------------------
These results clearly show the multiple equation nature of ordered logistic regression with
different constants and coefficients.The gologit command provides us with an alternative method for testing the proportionality assumption. If the assumption of proportional odds is tenable then there should not be a significant difference between the coefficients for academic in the two equations. The test command computes a Wald test across the two equations.
test [mleq1=mleq2]
( 1) [mleq1]academic - [mleq2]academic = 0.0
chi2( 1) = 1.98
Prob > chi2 = 0.1595
The results of the Wald test of proportionality are very similar to those found using the
omodel command.Let's rerun the ologit command followed by the listcoef and fitstat commands.
ologit ses academic
Ordered logit estimates Number of obs = 200
LR chi2(1) = 11.83
Prob > chi2 = 0.0006
Log likelihood = -204.66504 Pseudo R2 = 0.0281
------------------------------------------------------------------------------
ses | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
academic | .9299309 .2745004 3.39 0.001 .39192 1.467942
-------------+----------------------------------------------------------------
_cut1 | -.7643189 .2042487 (Ancillary parameters)
_cut2 | 1.41461 .225507
------------------------------------------------------------------------------
listcoef
ologit (N=200): Factor Change in Odds
Odds of: >m vs <=m
----------------------------------------------------------------------
ses | b z P>|z| e^b e^bStdX SDofX
-------------+--------------------------------------------------------
academic | 0.92993 3.388 0.001 2.5343 1.5929 0.5006
----------------------------------------------------------------------
fitstat
Measures of Fit for ologit of ses
Log-Lik Intercept Only: -210.583 Log-Lik Full Model: -204.665
D(197): 409.330 LR(1): 11.835
Prob > LR: 0.000
McFadden's R2: 0.028 McFadden's Adj R2: 0.014
Maximum Likelihood R2: 0.057 Cragg & Uhler's R2: 0.065
McKelvey and Zavoina's R2: 0.062
Variance of y*: 3.507 Variance of error: 3.290
Count R2: 0.475 Adj Count R2: 0.000
AIC: 2.077 AIC*n: 415.330
BIC: -634.438 BIC': -6.537
From the listcoef, we see that the relative risk ratio for academic is approximately 2.5, which
means that the risk (odds) of being in the high ses versus medium and low ses is 2.5 times greater for students
in the academic program. The same relative risk ratio also applies to the comparison of medium
and high ses versus low ses.Example 3
This example makes use of the dataset apcomp.dta. The variable apcomp contains the advanced placement composition score. Although ap scores can run from one to five our sample has no observations lower than two. Many colleges require a minimum score of three in order to count the ap course while some college require a minimum of four. The other variables in the file are female (1 if female), honors (1 if enrolled in any honors courses), and standardized test scores for reading, writing and logic (normed with mean=50 and sd=10).
use http://www.gseis.ucla.edu/courses/data/apcomp, clear
describe
Contains data from http://www.gseis.ucla.edu/courses/data/apcomp.dta
obs: 200
vars: 7 8 Feb 2001 20:09
size: 6,400 (99.9% of memory free)
-------------------------------------------------------------------------------
1. id float %9.0g
2. female float %9.0g fl
3. honors float %9.0g
4. read float %9.0g reading test
5. math float %9.0g math test
6. logic float %9.0g logic test
7. apcomp float %9.0g ap composition
-------------------------------------------------------------------------------
summarize
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
id | 200 100.5 57.87918 1 200
female | 200 .545 .4992205 0 1
honors | 200 .525 .5006277 0 1
read | 200 52.23 10.25294 28 76
math | 200 52.645 9.368448 33 75
logic | 200 51.85 9.900891 26 74
apcomp | 200 3.24 .9523312 2 5
tab1 female honors apcomp
-> tabulation of female
female | Freq. Percent Cum.
------------+-----------------------------------
male | 91 45.50 45.50
female | 109 54.50 100.00
------------+-----------------------------------
Total | 200 100.00
-> tabulation of honors
honors | Freq. Percent Cum.
------------+-----------------------------------
0 | 95 47.50 47.50
1 | 105 52.50 100.00
------------+-----------------------------------
Total | 200 100.00
-> tabulation of apcomp
ap |
composition | Freq. Percent Cum.
------------+-----------------------------------
2 | 49 24.50 24.50
3 | 77 38.50 63.00
4 | 51 25.50 88.50
5 | 23 11.50 100.00
------------+-----------------------------------
Total | 200 100.00
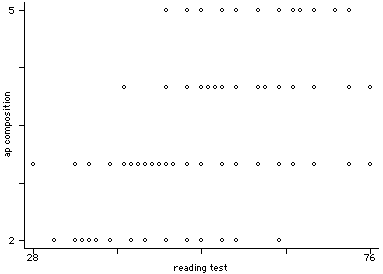
graph apcomp read
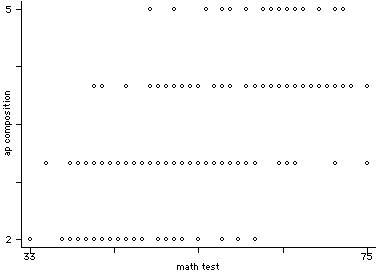
 graph apcomp math
graph apcomp math
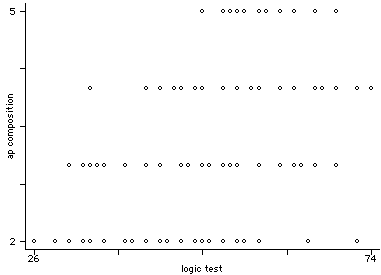
 graph apcomp logic
graph apcomp logic
 ologit apcomp read
Ordered logit estimates Number of obs = 200
LR chi2(1) = 76.66
Prob > chi2 = 0.0000
Log likelihood = -223.52071 Pseudo R2 = 0.1464
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
read | .1244339 .0155896 7.98 0.000 .0938788 .154989
-------------+----------------------------------------------------------------
_cut1 | 4.987403 .7694329 (Ancillary parameters)
_cut2 | 7.187831 .8594259
_cut3 | 9.100305 .946152
------------------------------------------------------------------------------
predict p1 p2 p3 p4
(option p assumed; predicted probabilities)
list apcomp p1 p2 p3 p4 in 1/20
apcomp p1 p2 p3 p4
1. 3 .10858 .415177 .357833 .11841
2. 4 .0300582 .188571 .4358533 .3455175
3. 2 .3804384 .466753 .1268567 .0259519
4. 2 .0545816 .2880693 .4365424 .2208068
5. 3 .2971326 .495265 .1703442 .0372582
6. 3 .3804384 .466753 .1268567 .0259519
7. 4 .2254312 .4989176 .2224301 .0532211
8. 3 .6806262 .2699708 .0417847 .0076183
9. 3 .0545816 .2880693 .4365424 .2208068
10. 3 .10858 .415177 .357833 .11841
11. 3 .0773699 .3535247 .4058594 .1632459
12. 5 .10858 .415177 .357833 .11841
13. 3 .0163624 .1142174 .3735782 .495842
14. 4 .1503285 .4646768 .300352 .0846427
15. 3 .3515753 .4788024 .1403323 .02929
16. 3 .4405771 .4361297 .1029425 .0203506
17. 3 .2971326 .495265 .1703442 .0372582
18. 3 .10858 .415177 .357833 .11841
19. 5 .0300582 .188571 .4358533 .3455175
20. 2 .1351161 .4500378 .3200508 .0947952
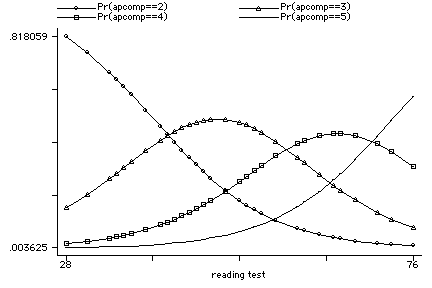
graph p1 p2 p3 p4 read, c(llll) sort
ologit apcomp read
Ordered logit estimates Number of obs = 200
LR chi2(1) = 76.66
Prob > chi2 = 0.0000
Log likelihood = -223.52071 Pseudo R2 = 0.1464
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
read | .1244339 .0155896 7.98 0.000 .0938788 .154989
-------------+----------------------------------------------------------------
_cut1 | 4.987403 .7694329 (Ancillary parameters)
_cut2 | 7.187831 .8594259
_cut3 | 9.100305 .946152
------------------------------------------------------------------------------
predict p1 p2 p3 p4
(option p assumed; predicted probabilities)
list apcomp p1 p2 p3 p4 in 1/20
apcomp p1 p2 p3 p4
1. 3 .10858 .415177 .357833 .11841
2. 4 .0300582 .188571 .4358533 .3455175
3. 2 .3804384 .466753 .1268567 .0259519
4. 2 .0545816 .2880693 .4365424 .2208068
5. 3 .2971326 .495265 .1703442 .0372582
6. 3 .3804384 .466753 .1268567 .0259519
7. 4 .2254312 .4989176 .2224301 .0532211
8. 3 .6806262 .2699708 .0417847 .0076183
9. 3 .0545816 .2880693 .4365424 .2208068
10. 3 .10858 .415177 .357833 .11841
11. 3 .0773699 .3535247 .4058594 .1632459
12. 5 .10858 .415177 .357833 .11841
13. 3 .0163624 .1142174 .3735782 .495842
14. 4 .1503285 .4646768 .300352 .0846427
15. 3 .3515753 .4788024 .1403323 .02929
16. 3 .4405771 .4361297 .1029425 .0203506
17. 3 .2971326 .495265 .1703442 .0372582
18. 3 .10858 .415177 .357833 .11841
19. 5 .0300582 .188571 .4358533 .3455175
20. 2 .1351161 .4500378 .3200508 .0947952
graph p1 p2 p3 p4 read, c(llll) sort
 ologit apcomp read math logic female honors
Ordered logit estimates Number of obs = 200
LR chi2(5) = 137.68
Prob > chi2 = 0.0000
Log likelihood = -193.01418 Pseudo R2 = 0.2629
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
read | .0562457 .0201711 2.788 0.005 .0167111 .0957803
math | .059579 .0232043 2.568 0.010 .0140993 .1050587
logic | .0814892 .0215118 3.788 0.000 .039327 .1236515
female | 1.495346 .3049343 4.904 0.000 .8976853 2.093006
honors | .8065409 .326349 2.471 0.013 .1669086 1.446173
---------+--------------------------------------------------------------------
_cut1 | 9.674563 1.174546 (Ancillary parameters)
_cut2 | 12.47571 1.321928
_cut3 | 14.72146 1.433348
------------------------------------------------------------------------------
ologit apcomp read math logic female honors
Ordered logit estimates Number of obs = 200
LR chi2(5) = 137.68
Prob > chi2 = 0.0000
Log likelihood = -193.01418 Pseudo R2 = 0.2629
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
read | .0562457 .0201711 2.788 0.005 .0167111 .0957803
math | .059579 .0232043 2.568 0.010 .0140993 .1050587
logic | .0814892 .0215118 3.788 0.000 .039327 .1236515
female | 1.495346 .3049343 4.904 0.000 .8976853 2.093006
honors | .8065409 .326349 2.471 0.013 .1669086 1.446173
---------+--------------------------------------------------------------------
_cut1 | 9.674563 1.174546 (Ancillary parameters)
_cut2 | 12.47571 1.321928
_cut3 | 14.72146 1.433348
------------------------------------------------------------------------------
In ordered logistic regression, Stata sets the constant to zero and estimates the cut points for
separating the various levels of the response variable. Other programs parameterize the model
differently by estimating the constant and setting the first cut point to zero.
Remember that ordered logistic regression is a multiequation model. In this
example, there are three equations, each with the same coefficients. This is a result of using
the proportional odds model. Other logistics regression models, which do not assume proportional
odds will have an equation (with constants and coefficients) for each of the k-1
equations.
Let's compare the results of the ordered logit with an ordered probit analysis.
oprobit apcomp read math logic female honors
Ordered probit estimates Number of obs = 200
LR chi2(5) = 137.41
Prob > chi2 = 0.0000
Log likelihood = -193.14592 Pseudo R2 = 0.2624
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
read | .0341779 .0116388 2.94 0.003 .0113663 .0569894
math | .0328021 .0132139 2.48 0.013 .0069033 .0587008
logic | .0461367 .0121744 3.79 0.000 .0222754 .069998
female | .8520197 .1721293 4.95 0.000 .5146526 1.189387
honors | .4456485 .1871253 2.38 0.017 .0788897 .8124073
-------------+----------------------------------------------------------------
_cut1 | 5.532786 .6302832 (Ancillary parameters)
_cut2 | 7.149652 .6965791
_cut3 | 8.422965 .7450567
------------------------------------------------------------------------------
The ordered probit is quite similar to the ordered logit with the ordered logit coefficients being
scaled about 1.7 times larger. Notice that the z-tests and p-values are quite similar.In fact, the results and interpretation of ordered logit and probit are so similar that we will focus on the ordered logit which is a bit more common and because the exponentiated coefficients in ordered logistic regression have a useful interpretation.
Now back to the ordered logit example.
ologit apcomp read math logic female honors
Ordered logit estimates Number of obs = 200
LR chi2(5) = 137.68
Prob > chi2 = 0.0000
Log likelihood = -193.01418 Pseudo R2 = 0.2629
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
read | .0562457 .0201711 2.788 0.005 .0167111 .0957803
math | .059579 .0232043 2.568 0.010 .0140993 .1050587
logic | .0814892 .0215118 3.788 0.000 .039327 .1236515
female | 1.495346 .3049343 4.904 0.000 .8976853 2.093006
honors | .8065409 .326349 2.471 0.013 .1669086 1.446173
---------+--------------------------------------------------------------------
_cut1 | 9.674563 1.174546 (Ancillary parameters)
_cut2 | 12.47571 1.321928
_cut3 | 14.72146 1.433348
------------------------------------------------------------------------------
test read = math
( 1) read - math = 0.0
chi2( 1) = 0.01
Prob > chi2 = 0.9239
test logic=honors
( 1) logic - honors = 0.0
chi2( 1) = 5.09
Prob > chi2 = 0.0241
listcoef
ologit (N=200): Factor Change in Odds
Odds of: >m vs <=m
------------------------------------------------------------------
apcomp | b z P>|z| e^b e^bStdX SDofX
---------+--------------------------------------------------------
read | 0.05625 2.788 0.005 1.0579 1.7801 10.2529
math | 0.05958 2.568 0.010 1.0614 1.7475 9.3684
logic | 0.08149 3.788 0.000 1.0849 2.2408 9.9009
female | 1.49535 4.904 0.000 4.4609 2.1096 0.4992
honors | 0.80654 2.471 0.013 2.2401 1.4975 0.5006
------------------------------------------------------------------
listcoef, percent
ologit (N=200): Percentage Change in Odds
Odds of: >m vs <=m
----------------------------------------------------------------------
apcomp | b z P>|z| % %StdX SDofX
-------------+--------------------------------------------------------
read | 0.05625 2.788 0.005 5.8 78.0 10.2529
math | 0.05958 2.568 0.010 6.1 74.7 9.3684
logic | 0.08149 3.788 0.000 8.5 124.1 9.9009
female | 1.49535 4.904 0.000 346.1 111.0 0.4992
honors | 0.80654 2.471 0.013 124.0 49.7 0.5006
----------------------------------------------------------------------
prchange
ologit: Changes in Predicted Probabilities for apcomp
read
Avg|Chg| 2 3 4 5
Min->Max .25370395 -.3382749 -.16913301 .38163372 .12577418
-+1/2 .00568587 -.00654036 -.00483137 .0092227 .00214906
-+sd/2 .05812593 -.06733277 -.04891908 .09398462 .02226725
MargEfct .02274416 -.00654009 -.00483199 .00922324 .00214884
math
Avg|Chg| 2 3 4 5
Min->Max .24448011 -.29404752 -.19491273 .36597994 .12298027
-+1/2 .00602282 -.006928 -.00511765 .0097692 .00227645
-+sd/2 .05626973 -.0651535 -.04738593 .09100176 .02153772
MargEfct .02409206 -.00692768 -.00511835 .00976984 .00227619
logic
Avg|Chg| 2 3 4 5
Min->Max .32934393 -.53561603 -.12307182 .46247212 .19621575
-+1/2 .00823751 -.00947613 -.0069989 .01336108 .00311392
-+sd/2 .08108919 -.0945658 -.06761259 .13070983 .03146856
MargEfct .03295193 -.00947534 -.00700062 .01336271 .00311326
female
Avg|Chg| 2 3 4 5
0->1 .14414695 -.18669248 -.10160142 .23067263 .05762128
honors
Avg|Chg| 2 3 4 5
0->1 .08036658 -.0959062 -.06482697 .12985113 .03088203
2 3 4 5
Pr(y|x) .13431878 .58434582 .24154782 .03978755
read math logic female honors
x= 52.23 52.645 51.85 .545 .525
sd(x)= 10.2529 9.36845 9.90089 .49922 .500628
prtab female
ologit: Predicted probabilities for apcomp
Predicted probability of outcome 2
----------------------
female | Prediction
----------+-----------
male | 0.2595
female | 0.0729
----------------------
Predicted probability of outcome 3
----------------------
female | Prediction
----------+-----------
male | 0.5928
female | 0.4912
----------------------
Predicted probability of outcome 4
----------------------
female | Prediction
----------+-----------
male | 0.1297
female | 0.3604
----------------------
Predicted probability of outcome 5
----------------------
female | Prediction
----------+-----------
male | 0.0180
female | 0.0756
----------------------
read math logic female honors
x= 52.23 52.645 51.85 .545 .525
linktest
Ordered logit estimates Number of obs = 200
LR chi2(2) = 139.58
Prob > chi2 = 0.0000
Log likelihood = -192.06405 Pseudo R2 = 0.2665
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_hat | 2.253344 .9396528 2.40 0.016 .4116582 4.09503
_hatsq | -.0530971 .0391868 -1.35 0.175 -.1299019 .0237077
-------------+----------------------------------------------------------------
_cut1 | 16.8746 5.52804 (Ancillary parameters)
_cut2 | 19.74618 5.622571
_cut3 | 21.90726 5.596362
------------------------------------------------------------------------------Since the _hatsq variable is not statistically significant this model passes the link test.
Next, we will check the proportional odds assumption using the brant command (findit brant).
omodel logit apcomp read math logic female honors
Brant Test of Parallel Regression Assumption
Variable | chi2 p>chi2 df
-------------+--------------------------
All | 5.61 0.847 10
-------------+--------------------------
read | 0.02 0.992 2
math | 0.10 0.950 2
logic | 0.95 0.623 2
female | 3.08 0.215 2
honors | 1.42 0.490 2
----------------------------------------
A significant test statistic provides evidence that the parallel
regression assumption has been violated.The chi-square test of proportional odds is not significant, suggesting that the proportional odds assumptions holds for this model.
If we had found that the proportional odds assumption was not being met we could use the gologit command (findit gologit). We will go ahead and demonstrate gologit again even though it isn't needed.
gologit apcomp read math logic female honors
Generalized Ordered Logit Estimates Number of obs = 200
Model chi2(15) = 142.21
Prob > chi2 = 0.0000
Log Likelihood = -190.7486768 Pseudo R2 = 0.2715
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
mleq1 |
read | .054418 .0317229 1.72 0.086 -.0077577 .1165937
math | .0532747 .0352761 1.51 0.131 -.0158652 .1224145
logic | .0901152 .030791 2.93 0.003 .0297659 .1504644
female | 2.073289 .463178 4.48 0.000 1.165477 2.981101
honors | 1.031883 .4841714 2.13 0.033 .0829247 1.980842
_cons | -10.04631 1.805057 -5.57 0.000 -13.58416 -6.508466
-------------+----------------------------------------------------------------
mleq2 |
read | .0562999 .0254822 2.21 0.027 .0063558 .1062441
math | .0628903 .0300689 2.09 0.036 .0039563 .1218244
logic | .0796853 .0287587 2.77 0.006 .0233192 .1360514
female | 1.22661 .4046231 3.03 0.002 .4335634 2.019657
honors | .7753164 .4190188 1.85 0.064 -.0459454 1.596578
_cons | -12.35719 1.740698 -7.10 0.000 -15.76889 -8.945482
-------------+----------------------------------------------------------------
mleq3 |
read | .069526 .0349572 1.99 0.047 .0010111 .1380408
math | .0701937 .0412247 1.70 0.089 -.0106053 .1509927
logic | .0496247 .0415333 1.19 0.232 -.031779 .1310285
female | .8766584 .5498442 1.59 0.111 -.2010165 1.954333
honors | .3158829 .6248025 0.51 0.613 -.9087075 1.540473
_cons | -13.51632 2.560114 -5.28 0.000 -18.53405 -8.498588
------------------------------------------------------------------------------
At this point it might be interesting to run the model using multinomial logistic regression
to see how the coefficients differ when the information concerning the ordering of the
categories is ignored. mlogit models the four levels of apcomp but does not consider
the order to be relevant.
mlogit apcomp read math logic female honors
Multinomial regression Number of obs = 200
LR chi2(15) = 143.87
Prob > chi2 = 0.0000
Log likelihood = -189.91916 Pseudo R2 = 0.2747
------------------------------------------------------------------------------
apcomp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
2 |
read | -.0502566 .0337895 -1.49 0.137 -.1164829 .0159696
math | -.0390346 .0367579 -1.06 0.288 -.1110787 .0330095
logic | -.0718204 .0309605 -2.32 0.020 -.1325019 -.0111389
female | -1.926365 .4853799 -3.97 0.000 -2.877692 -.9750375
honors | -.9097543 .4955603 -1.84 0.066 -1.881035 .0615261
_cons | 8.475003 1.96647 4.31 0.000 4.620792 12.32921
-------------+----------------------------------------------------------------
4 |
read | .0437103 .0284908 1.53 0.125 -.0121307 .0995512
math | .0441517 .032509 1.36 0.174 -.0195647 .1078682
logic | .0722122 .0326006 2.22 0.027 .0083162 .1361082
female | .795977 .4551482 1.75 0.080 -.096097 1.688051
honors | .6721123 .4609678 1.46 0.145 -.231368 1.575593
_cons | -9.980668 2.041438 -4.89 0.000 -13.98181 -5.979522
-------------+----------------------------------------------------------------
5 |
read | .0899533 .040053 2.25 0.025 .0114508 .1684558
math | .0929354 .0462658 2.01 0.045 .0022561 .1836148
logic | .0784435 .0489755 1.60 0.109 -.0175466 .1744336
female | 1.28734 .6325883 2.04 0.042 .0474901 2.52719
honors | .4093816 .6989465 0.59 0.558 -.9605284 1.779292
_cons | -16.96368 3.145567 -5.39 0.000 -23.12888 -10.79848
------------------------------------------------------------------------------
(Outcome apcomp==3 is the comparison group)
Example 4This example from Richard Williams (Notre Dame) will allow us to investigate the use of the gologit2 command (findit gologit2). gologit2 allows for several different options for relaxing the proportional odds assumption for all or a selected subset of the predictors.
gologit2 was written by Richard Williams (2005).
use http://www.gseis.ucla.edu/courses/data/ordwarm2.dta, clear
ologit warm yr89 male white age ed prst
Ordered logistic regression Number of obs = 2293
LR chi2(6) = 301.72
Prob > chi2 = 0.0000
Log likelihood = -2844.9123 Pseudo R2 = 0.0504
------------------------------------------------------------------------------
warm | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
yr89 | .5239025 .0798988 6.56 0.000 .3673037 .6805013
male | -.7332997 .0784827 -9.34 0.000 -.8871229 -.5794766
white | -.3911595 .1183808 -3.30 0.001 -.6231815 -.1591374
age | -.0216655 .0024683 -8.78 0.000 -.0265032 -.0168278
ed | .0671728 .015975 4.20 0.000 .0358624 .0984831
prst | .0060727 .0032929 1.84 0.065 -.0003813 .0125267
-------------+----------------------------------------------------------------
/cut1 | -2.465362 .2389126 -2.933622 -1.997102
/cut2 | -.630904 .2333155 -1.088194 -.173614
/cut3 | 1.261854 .2340179 .8031873 1.720521
------------------------------------------------------------------------------
brant
Brant Test of Parallel Regression Assumption
Variable | chi2 p>chi2 df
-------------+--------------------------
All | 49.18 0.000 12
-------------+--------------------------
yr89 | 13.01 0.001 2
male | 22.24 0.000 2
white | 1.27 0.531 2
age | 7.38 0.025 2
ed | 4.31 0.116 2
prst | 4.33 0.115 2
----------------------------------------
A significant test statistic provides evidence that the parallel
regression assumption has been violated.
Okay, we know that the proportional odds assumption does not hold for this model. And we
know further that the variables yr89 and male are the major offenders along with
possibly age. So, we will run three different gologit2 models saving information
on each one to compare them.
/* model 1 -- with proportional odds assumption -- same as ologit */
gologit2 warm yr89 male white age ed prst, pl store(m1)
Generalized Ordered Logit Estimates Number of obs = 2293
Wald chi2(6) = 285.47
Prob > chi2 = 0.0000
Log likelihood = -2844.9123 Pseudo R2 = 0.0504
( 1) [SD]yr89 - [D]yr89 = 0
( 2) [SD]male - [D]male = 0
( 3) [SD]white - [D]white = 0
( 4) [SD]age - [D]age = 0
( 5) [SD]ed - [D]ed = 0
( 6) [SD]prst - [D]prst = 0
( 7) [D]yr89 - [A]yr89 = 0
( 8) [D]male - [A]male = 0
( 9) [D]white - [A]white = 0
(10) [D]age - [A]age = 0
(11) [D]ed - [A]ed = 0
(12) [D]prst - [A]prst = 0
------------------------------------------------------------------------------
warm | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
SD |
yr89 | .5239025 .0798989 6.56 0.000 .3673036 .6805014
male | -.7332998 .0784827 -9.34 0.000 -.887123 -.5794765
white | -.3911595 .1183808 -3.30 0.001 -.6231816 -.1591373
age | -.0216655 .0024683 -8.78 0.000 -.0265032 -.0168278
ed | .0671728 .015975 4.20 0.000 .0358624 .0984831
prst | .0060727 .0032929 1.84 0.065 -.0003813 .0125267
_cons | 2.465362 .2389128 10.32 0.000 1.997102 2.933622
-------------+----------------------------------------------------------------
D |
yr89 | .5239025 .0798989 6.56 0.000 .3673036 .6805014
male | -.7332998 .0784827 -9.34 0.000 -.887123 -.5794765
white | -.3911595 .1183808 -3.30 0.001 -.6231816 -.1591373
age | -.0216655 .0024683 -8.78 0.000 -.0265032 -.0168278
ed | .0671728 .015975 4.20 0.000 .0358624 .0984831
prst | .0060727 .0032929 1.84 0.065 -.0003813 .0125267
_cons | .630904 .2333156 2.70 0.007 .1736138 1.088194
-------------+----------------------------------------------------------------
A |
yr89 | .5239025 .0798989 6.56 0.000 .3673036 .6805014
male | -.7332998 .0784827 -9.34 0.000 -.887123 -.5794765
white | -.3911595 .1183808 -3.30 0.001 -.6231816 -.1591373
age | -.0216655 .0024683 -8.78 0.000 -.0265032 -.0168278
ed | .0671728 .015975 4.20 0.000 .0358624 .0984831
prst | .0060727 .0032929 1.84 0.065 -.0003813 .0125267
_cons | -1.261854 .234018 -5.39 0.000 -1.720521 -.8031871
------------------------------------------------------------------------------
/* model 2 -- full generalized ologit with no parallel line */
gologit2 warm yr89 male white age ed prst, npl store(m2)
Generalized Ordered Logit Estimates Number of obs = 2293
LR chi2(18) = 350.92
Prob > chi2 = 0.0000
Log likelihood = -2820.311 Pseudo R2 = 0.0586
------------------------------------------------------------------------------
warm | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
SD |
yr89 | .95575 .1547185 6.18 0.000 .6525074 1.258993
male | -.3009776 .1287712 -2.34 0.019 -.5533645 -.0485906
white | -.5287268 .2278446 -2.32 0.020 -.9752941 -.0821595
age | -.0163486 .0039508 -4.14 0.000 -.0240921 -.0086051
ed | .1032469 .0247377 4.17 0.000 .0547619 .151732
prst | -.0016912 .0055997 -0.30 0.763 -.0126665 .009284
_cons | 1.856951 .3872576 4.80 0.000 1.09794 2.615962
-------------+----------------------------------------------------------------
D |
yr89 | .5363707 .0919074 5.84 0.000 .3562355 .716506
male | -.717995 .0894852 -8.02 0.000 -.8933827 -.5426072
white | -.349234 .1391882 -2.51 0.012 -.6220379 -.07643
age | -.0249764 .0028053 -8.90 0.000 -.0304747 -.0194782
ed | .0558691 .0183654 3.04 0.002 .0198737 .0918646
prst | .0098476 .0038216 2.58 0.010 .0023575 .0173377
_cons | .7198119 .265235 2.71 0.007 .1999609 1.239663
-------------+----------------------------------------------------------------
A |
yr89 | .3312184 .1127882 2.94 0.003 .1101577 .5522792
male | -1.085618 .1217755 -8.91 0.000 -1.324294 -.8469423
white | -.3775375 .1568429 -2.41 0.016 -.684944 -.070131
age | -.0186902 .0037291 -5.01 0.000 -.025999 -.0113814
ed | .0566852 .0251836 2.25 0.024 .0073263 .1060441
prst | .0049225 .0048543 1.01 0.311 -.0045918 .0144368
_cons | -1.002225 .3446354 -2.91 0.004 -1.677698 -.3267523
------------------------------------------------------------------------------
lrtest m1 m2
Likelihood-ratio test LR chi2(12) = 49.20
(Assumption: m1 nested in m2) Prob > chi2 = 0.0000
/* model 3 -- relax parallel assumption on yr89 and male only */
gologit2 warm yr89 male white age ed prst, npl(yr89 male) store(m3)
Generalized Ordered Logit Estimates Number of obs = 2293
Wald chi2(10) = 312.92
Prob > chi2 = 0.0000
Log likelihood = -2826.6182 Pseudo R2 = 0.0565
( 1) [SD]white - [D]white = 0
( 2) [SD]age - [D]age = 0
( 3) [SD]ed - [D]ed = 0
( 4) [SD]prst - [D]prst = 0
( 5) [D]white - [A]white = 0
( 6) [D]age - [A]age = 0
( 7) [D]ed - [A]ed = 0
( 8) [D]prst - [A]prst = 0
------------------------------------------------------------------------------
warm | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
SD |
yr89 | .98368 .1530091 6.43 0.000 .6837876 1.283572
male | -.3328209 .1275129 -2.61 0.009 -.5827417 -.0829002
white | -.3832583 .1184635 -3.24 0.001 -.6154424 -.1510742
age | -.0216325 .0024751 -8.74 0.000 -.0264835 -.0167814
ed | .0670703 .0161311 4.16 0.000 .0354539 .0986866
prst | .0059146 .0033158 1.78 0.074 -.0005843 .0124135
_cons | 2.12173 .2467146 8.60 0.000 1.638178 2.605282
-------------+----------------------------------------------------------------
D |
yr89 | .534369 .0913937 5.85 0.000 .3552406 .7134974
male | -.6932772 .0885898 -7.83 0.000 -.8669099 -.5196444
white | -.3832583 .1184635 -3.24 0.001 -.6154424 -.1510742
age | -.0216325 .0024751 -8.74 0.000 -.0264835 -.0167814
ed | .0670703 .0161311 4.16 0.000 .0354539 .0986866
prst | .0059146 .0033158 1.78 0.074 -.0005843 .0124135
_cons | .6021625 .2358361 2.55 0.011 .1399323 1.064393
-------------+----------------------------------------------------------------
A |
yr89 | .3258098 .1125481 2.89 0.004 .1052197 .5464
male | -1.097615 .1214597 -9.04 0.000 -1.335671 -.8595579
white | -.3832583 .1184635 -3.24 0.001 -.6154424 -.1510742
age | -.0216325 .0024751 -8.74 0.000 -.0264835 -.0167814
ed | .0670703 .0161311 4.16 0.000 .0354539 .0986866
prst | .0059146 .0033158 1.78 0.074 -.0005843 .0124135
_cons | -1.048137 .2393568 -4.38 0.000 -1.517268 -.5790061
------------------------------------------------------------------------------
lrtest m1 m3
Likelihood-ratio test LR chi2(4) = 36.59
(Assumption: m1 nested in m3) Prob > chi2 = 0.0000
lrtest m2 m3
Likelihood-ratio test LR chi2(8) = 12.61
(Assumption: m3 nested in m2) Prob > chi2 = 0.1258
Because Model 3 is significantly different from Model 1 and not significantly different from Model 2
we will go with Model 3 in which the proportionality assumption holds for all variables
except for yr89 and male. There is no need to relax the proportionality
assumption for age.Finally, we will rerun the last model using the gamma parameterization.
gologit2, gamma
(output omitted)
Alternative parameterization: Gammas are deviations from proportionality
------------------------------------------------------------------------------
warm | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
Beta |
yr89 | .98368 .1530091 6.43 0.000 .6837876 1.283572
male | -.3328209 .1275129 -2.61 0.009 -.5827417 -.0829002
white | -.3832583 .1184635 -3.24 0.001 -.6154424 -.1510742
age | -.0216325 .0024751 -8.74 0.000 -.0264835 -.0167814
ed | .0670703 .0161311 4.16 0.000 .0354539 .0986866
prst | .0059146 .0033158 1.78 0.074 -.0005843 .0124135
-------------+----------------------------------------------------------------
Gamma_2 |
yr89 | -.449311 .1465627 -3.07 0.002 -.7365686 -.1620533
male | -.3604562 .1233732 -2.92 0.003 -.6022633 -.1186492
-------------+----------------------------------------------------------------
Gamma_3 |
yr89 | -.6578702 .1768034 -3.72 0.000 -1.004399 -.3113418
male | -.7647937 .1631536 -4.69 0.000 -1.084569 -.4450186
-------------+----------------------------------------------------------------
Alpha |
_cons_1 | 2.12173 .2467146 8.60 0.000 1.638178 2.605282
_cons_2 | .6021625 .2358361 2.55 0.011 .1399323 1.064393
_cons_3 | -1.048137 .2393568 -4.38 0.000 -1.517268 -.5790061
------------------------------------------------------------------------------
The alternative gamma parameterization presents an equivalent parameterization of the
gologit model, called the unconstrained partial proportional odds model. The model
has one ordered logistic coefficient, beta, for each predictor, M-2 gamma coeffi�cients representing
deviations from proportionality (where M equals the number of categories in the response variable),
and M-1 alpha coefficients reflecting the cut points.The gamma_2 value for yr89 (-.449311) is added to beta (.98368) yielding the value for the coefficient in equation D above (.534369 = .98368 - .449311). The same process is used to get the coefficident for yr89 in equation A above (.3258098 = .98368 - .6578702).
This gamma parameterization combines the best of the traditional ologit output while allowing for nonproportionality in some or all of the variables in the model.
Categorical Data Analysis Course
Phil Ender -- 7mar06, 12may05