Generalized estimating equations are used in cross-sectional time-series models. In particular, GEE models estimate generalized linear models and allow for the specification of the within-group correlation structure for the panels, which are also known as population-averaged panel-data models.
As in GLM models, users specify a distribution family for the random component and a link function to transform the expected values. In addition, GEE models allow for repeated or dependent observations and the ability to specify the correlation structure.
When an independent correlation structure is specified, the analysis is the same as OLS regression, ignoring the lack of independence among the observations. A correlational structure of exchangeable is equivalent to the compound symmetry assumptions found in randomized-block type anova designs. Unstructured correlations are equivalent to a multivariate analysis of the observations. GEE models can also allow for other structures, such as, autoregressive or stationary.
Example with Interval Response Variable
These data are adapted from a 1996 study (Gregoire, Kumar Everitt, Henderson & Studd) on the efficacy of estrogen patches in treating postnatal depression. Women were randomly assigned to either a placebo control group (group=0, n=27) or estrogen patch group (group=1, n=34). Prior to the first treatment all patients took the Edinburgh Postnatal Depression Scale (EPDS). EPDS data was collected monthly for six months once the treatment began. Higher scores on the EDPS are indicative of higher levels of depression.
Before reading in the data we will need to change the size of the largest matrix that Stata can use. We need to do this because one of the analyses requires a large number of coded variables:
set matsize 160 use http://www.gseis.ucla.edu/courses/data/depress
Note that the data are in the wide format, we will collect some information and perform a couple of analyses while the data are in this format.
sort group
by group: summarize pre dep1 dep2 dep3 dep4 dep5 dep6
-> group= 0
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
pre | 27 20.77778 3.954874 15 28
dep1 | 27 16.48148 5.279644 7 26
dep2 | 22 15.88818 6.124177 4 27
dep3 | 17 14.12882 4.974648 4.19 22
dep4 | 17 12.27471 5.848791 2 23
dep5 | 17 11.40294 4.438702 3.03 18
dep6 | 17 10.89588 4.68157 3.45 20
-> group= 1
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
pre | 34 21.24882 3.574432 15 28
dep1 | 34 13.36794 5.556373 1 27
dep2 | 31 11.73677 6.575079 1 27
dep3 | 29 9.134138 5.475564 1 24
dep4 | 28 8.827857 4.666653 0 22
dep5 | 28 7.309286 5.740988 0 24
dep6 | 28 6.590714 4.730158 1 23
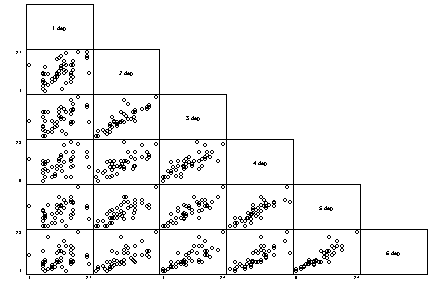
corr pre dep1 dep2 dep3 dep4 dep5 dep6
(obs=45)
| pre dep1 dep2 dep3 dep4 dep5 dep6
---------+---------------------------------------------------------------
pre | 1.0000
dep1 | 0.1922 1.0000
dep2 | 0.3904 0.4982 1.0000
dep3 | 0.3958 0.5258 0.8672 1.0000
dep4 | 0.1658 0.3933 0.7357 0.7831 1.0000
dep5 | 0.2848 0.3674 0.7500 0.8520 0.8449 1.0000
dep6 | 0.2688 0.2795 0.6900 0.7967 0.7894 0.9014 1.0000
graph dep1 dep2 dep3 dep4 dep5 dep6, matrix half
Let's check to see if the groups differ on the pretest depression score:
ttest pre, by(group)
Two-sample t test with equal variances
------------------------------------------------------------------------------
Group | Obs Mean Std. Err. Std. Dev. [95% Conf. Interval]
---------+--------------------------------------------------------------------
0 | 27 20.77778 .7611158 3.954874 19.21328 22.34227
1 | 34 21.24882 .61301 3.574432 20.00165 22.496
---------+--------------------------------------------------------------------
combined | 61 21.04033 .476678 3.722975 20.08683 21.99383
---------+--------------------------------------------------------------------
diff | -.4710457 .9658499 -2.403707 1.461615
------------------------------------------------------------------------------
Degrees of freedom: 59
Ho: mean(0) - mean(1) = diff = 0
Ha: diff < 0 Ha: diff ~= 0 Ha: diff > 0
t = -0.4877 t = -0.4877 t = -0.4877
P < t = 0.3138 P > |t| = 0.6276 P > t = 0.6862
There isn't much of a difference between groups on the pretest so let's try a Hotelling's T2
hotel dep1 dep2 dep3 dep4 dep5 dep6, by(group)
-> group= 0
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
dep1 | 17 16.58824 5.657504 7 26
dep2 | 17 14.97294 6.077413 4 24
dep3 | 17 14.12882 4.974648 4.19 22
dep4 | 17 12.27471 5.848791 2 23
dep5 | 17 11.40294 4.438702 3.03 18
dep6 | 17 10.89588 4.68157 3.45 20
-> group= 1
Variable | Obs Mean Std. Dev. Min Max
---------+-----------------------------------------------------
dep1 | 28 12.9825 5.565811 1 27
dep2 | 28 11.17286 6.333161 1 27
dep3 | 28 8.924643 5.456403 1 24
dep4 | 28 8.827857 4.666653 0 22
dep5 | 28 7.309286 5.740988 0 24
dep6 | 28 6.590714 4.730158 1 23
2-group Hotelling's T-squared = 16.373757
F test statistic: ((45-6-1)/(45-2)(6)) x 16.373757 = 2.4116387
H0: Vectors of means are equal for the two groups
F(6,38) = 2.4116
Pr > F(6,38) = 0.0450Using Hotelling's T2 we find a significant difference between the two groups. The T2 did not make use of any of the information concerning the pretest but that's okay for the moment especially since we know that the pretest differences were not significant.
Using manova we can try the exact same analysis
manova dep1 dep2 dep3 dep4 dep5 dep6 = group
Number of obs = 45
W = Wilks' lambda L = Lawley-Hotelling trace
P = Pillai's trace R = Roy's largest root
Source | Statistic df F(df1, df2) = F Prob>F
-----------+--------------------------------------------------
group | W 0.7242 1 6.0 38.0 2.41 0.0450 e
| P 0.2758 6.0 38.0 2.41 0.0450 e
| L 0.3808 6.0 38.0 2.41 0.0450 e
| R 0.3808 6.0 38.0 2.41 0.0450 e
|--------------------------------------------------
Residual | 43
-----------+--------------------------------------------------
Total | 44
--------------------------------------------------------------
e = exact, a = approximate, u = upper bound on FNow it is time to reshape the data and try some other analyses:
reshape long dep, i(subj) j(visit)
(note: j = 1 2 3 4 5 6)
Data wide -> long
-----------------------------------------------------------------------------
Number of obs. 61 -> 366
Number of variables 9 -> 5
j variable (6 values) -> visit
xij variables:
dep1 dep2 ... dep6 -> dep
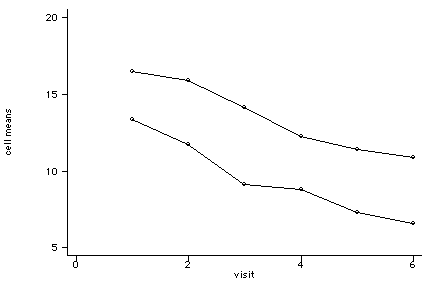
-----------------------------------------------------------------------------Let's plot the means by group and visit by making use of the cmeans procedure. cmeans is not part of Stata and needs to be downloded onto your system in order to make use of it.
cmeans dep group visit /* Available from ATS */
Let's try an analysis of variance. This is the analysis that requires the larger matrix size.
anova dep group / subj|group visit group*visit /, repeated(visit)
Number of obs = 295 R-squared = 0.7699
Root MSE = 3.39594 Adj R-squared = 0.6980
Source | Partial SS df MS F Prob > F
------------+----------------------------------------------------
Model | 8643.81572 70 123.483082 10.71 0.0000
|
group | 548.494938 1 548.494938 5.60 0.0212
subj|group | 5775.54143 59 97.8905328
------------+----------------------------------------------------
visit | 1050.05444 5 210.010889 18.21 0.0000
group*visit | 19.3028953 5 3.86057906 0.33 0.8916
|
Residual | 2583.26536 224 11.5324346
------------+----------------------------------------------------
Total | 11227.0811 294 38.1873506
Between-subjects error term: subj|group
Levels: 61 (59 df)
Lowest b.s.e. variable: subj
Covariance pooled over: group (for repeated variable)
Repeated variable: visit
Huynh-Feldt epsilon = 0.5930
Greenhouse-Geisser epsilon = 0.5532
Box's conservative epsilon = 0.2000
------------ Prob > F ------------
Source | df F Regular H-F G-G Box
------------+----------------------------------------------------
visit | 5 18.21 0.0000 0.0000 0.0000 0.0001
group*visit | 5 0.33 0.8916 0.7979 0.7840 0.5658
Residual | 224
------------+----------------------------------------------------
matrix list e(Srep)
symmetric e(Srep)[6,6]
c1 c2 c3 c4 c5 c6
r1 31.361171
r2 15.71989 38.927914
r3 13.555927 28.365674 27.90249
r4 9.4625252 22.74371 20.519069 26.403025
r5 8.6149335 23.887935 23.161248 22.47211 28.026157
r6 4.6830378 19.242424 18.721233 18.46616 22.103924 22.204237This analysis indicates that both group and visit are significant while the group*visit interaction is not. Some researchers are critical of this type of analysis since it is based on fixed-effects adjusted for the repeated factor. Also, this repeated measures analysis assumes compound symmetry in the covariance matrix (which seems to be a stretch in this case). However, we can do worse. The next several analyses are not meant to answer the research question but to show relationships among several different commands in Stata.
regress dep pre group visit
Source | SS df MS Number of obs = 295
---------+------------------------------ F( 3, 291) = 48.05
Model | 3719.12931 3 1239.70977 Prob > F = 0.0000
Residual | 7507.95176 291 25.8005215 R-squared = 0.3313
---------+------------------------------ Adj R-squared = 0.3244
Total | 11227.0811 294 38.1873506 Root MSE = 5.0794
------------------------------------------------------------------------------
dep | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .4769071 .0798565 5.972 0.000 .3197376 .6340767
group | -4.290664 .6072954 -7.065 0.000 -5.485912 -3.095416
visit | -1.307841 .169842 -7.700 0.000 -1.642116 -.9735667
_cons | 8.233577 1.803945 4.564 0.000 4.683143 11.78401
------------------------------------------------------------------------------
regress dep pre group visit, cluster(subj)
Regression with robust standard errors Number of obs = 295
F( 3, 60) = 32.19
Prob > F = 0.0000
R-squared = 0.3313
Number of clusters (subj) = 61 Root MSE = 5.0794
------------------------------------------------------------------------------
| Robust
dep | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
pre | .4769071 .1749723 2.73 0.008 .1269105 .8269038
group | -4.290664 1.085895 -3.95 0.000 -6.462777 -2.118551
visit | -1.307841 .1721679 -7.60 0.000 -1.652228 -.9634542
_cons | 8.233577 3.863708 2.13 0.037 .5050103 15.96214
------------------------------------------------------------------------------
glm dep pre group visit, fam(gaus) link(iden)
Iteration 1 : deviance = 7507.9518
Residual df = 291 No. of obs = 295
Pearson X2 = 7507.952 Deviance = 7507.952
Dispersion = 25.80052 Dispersion = 25.80052
Gaussian (normal) distribution, identity link
------------------------------------------------------------------------------
dep | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .4769071 .0798565 5.972 0.000 .3197376 .6340767
group | -4.290664 .6072954 -7.065 0.000 -5.485912 -3.095416
visit | -1.307841 .169842 -7.700 0.000 -1.642116 -.9735667
_cons | 8.233577 1.803945 4.564 0.000 4.683143 11.78401
------------------------------------------------------------------------------
(Model is ordinary regression, use regress instead)
xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(ind)
Iteration 1: tolerance = 3.270e-15
GEE population-averaged model Number of obs = 295
Group variable: subj Number of groups = 61
Link: identity Obs per group: min = 1
Family: Gaussian avg = 4.8
Correlation: independent max = 6
Wald chi2(3) = 146.13
Scale parameter: 25.45068 Prob > chi2 = 0.0000
Pearson chi2(295): 7507.95 Deviance = 7507.95
Dispersion (Pearson): 25.45068 Dispersion = 25.45068
------------------------------------------------------------------------------
dep | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .4769071 .0793133 6.013 0.000 .321456 .6323582
group | -4.290664 .6031641 -7.114 0.000 -5.472844 -3.108484
visit | -1.307841 .1686866 -7.753 0.000 -1.638461 -.9772215
_cons | 8.233577 1.791673 4.595 0.000 4.721962 11.74519
------------------------------------------------------------------------------
xtcorr
Estimated within-subj correlation matrix R:
c1 c2 c3 c4 c5 c6
r1 1.0000
r2 0.0000 1.0000
r3 0.0000 0.0000 1.0000
r4 0.0000 0.0000 0.0000 1.0000
r5 0.0000 0.0000 0.0000 0.0000 1.0000
r6 0.0000 0.0000 0.0000 0.0000 0.0000 1.0000
The three previous analyses provide identical incorrect results. The common thread among them is that they all assume that the observations within the subjects are independent. This seems, on the face of it, to be highly unlikely. Scores on the depression scale are not likely to be independent from one visit to the next. Of the three, only xtgee makes the assumption concerning the correlations explicit. The xtcorr command shows structure of the correlation matrix.
xt commands are used with cross-sectional time-series data. These data are also referred to as panel data. Here is a descriptive command we can use to look at the data.
xtsum
Variable | Mean Std. Dev. Min Max | Observations
-----------------+--------------------------------------------+----------------
subj overall | 31 17.63092 1 61 | N = 366
between | 17.75293 1 61 | n = 61
within | 0 31 31 | T = 6
| |
visit overall | 3.5 1.710163 1 6 | N = 366
between | 0 3.5 3.5 | n = 61
within | 1.710163 1 6 | T = 6
| |
dep overall | 11.32915 6.179591 0 27 | N = 295
between | 5.407777 2 26.5 | n = 61
within | 3.566633 1.662486 27.32915 | T = 4.83607
| |
group overall | .557377 .4973769 0 1 | N = 366
between | .500819 0 1 | n = 61
within | 0 .557377 .557377 | T = 6
| |
pre overall | 21.04033 3.697387 15 28 | N = 366
between | 3.722975 15 28 | n = 61
within | 0 21.04033 21.04033 | T = 6
We can analyze these data using compound symmetry for the correlational structure. This approach can be tried using exchangeable for the correlation matrix in xtgee.
xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(exc)
GEE population-averaged model Number of obs = 295
Group variable: subj Number of groups = 61
Link: identity Obs per group: min = 1
Family: Gaussian avg = 4.8
Correlation: exchangeable max = 6
Wald chi2(3) = 135.08
Scale parameter: 25.56569 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
dep | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .4599018 .1441533 3.190 0.001 .1773666 .742437
group | -4.024676 1.081131 -3.723 0.000 -6.143654 -1.905698
visit | -1.226764 .1175009 -10.440 0.000 -1.457062 -.9964666
_cons | 8.432806 3.120987 2.702 0.007 2.315783 14.54983
-----------------------------------------------------------------------------
xtcorr
Estimated within-subj correlation matrix R:
c1 c2 c3 c4 c5 c6
r1 1.0000
r2 0.5554 1.0000
r3 0.5554 0.5554 1.0000
r4 0.5554 0.5554 0.5554 1.0000
r5 0.5554 0.5554 0.5554 0.5554 1.0000
r6 0.5554 0.5554 0.5554 0.5554 0.5554 1.0000
Note in particular the change in the standard errors between this analysis and the previous one. Now let's try a different correlation structure, auto regressive with lag one.
xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(ar1)
GEE population-averaged model Number of obs = 287
Group and time vars: subj visit Number of groups = 53
Link: identity Obs per group: min = 2
Family: Gaussian avg = 5.4
Correlation: AR(1) max = 6
Wald chi2(3) = 64.55
Scale parameter: 25.82413 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
dep | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .4268002 .1376156 3.101 0.002 .1570785 .6965219
group | -4.218194 1.053504 -4.004 0.000 -6.283023 -2.153364
visit | -1.181975 .1907298 -6.197 0.000 -1.555799 -.8081517
_cons | 9.037864 3.036076 2.977 0.003 3.087264 14.98846
------------------------------------------------------------------------------
xtcorr
Estimated within-subj correlation matrix R:
c1 c2 c3 c4 c5 c6
r1 1.0000
r2 0.6812 1.0000
r3 0.4641 0.6812 1.0000
r4 0.3161 0.4641 0.6812 1.0000
r5 0.2154 0.3161 0.4641 0.6812 1.0000
r6 0.1467 0.2154 0.3161 0.4641 0.6812 1.000
This analysis probably more closely reflects the correlations among the depression scores over six visits that we observed in our descriptive analysis. However, we can carry our study of correlation structure one step further. What if we impose no preconceived notions about the correlations. In this instance, we will request an unstructured correlation matrix.
xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(unstr)
GEE population-averaged model Number of obs = 295
Group and time vars: subj visit Number of groups = 61
Link: identity Obs per group: min = 1
Family: Gaussian avg = 4.8
Correlation: unstructured max = 6
Wald chi2(3) = 94.13
Scale parameter: 25.87029 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
dep | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .3399185 .1326684 2.562 0.010 .0798932 .5999437
group | -4.134413 .9986306 -4.140 0.000 -6.091693 -2.177133
visit | -1.228327 .1492831 -8.228 0.000 -1.520916 -.9357372
_cons | 11.13045 2.892903 3.848 0.000 5.460464 16.80044
------------------------------------------------------------------------------
xtcorr
Estimated within-subj correlation matrix R:
c1 c2 c3 c4 c5 c6
r1 1.0000
r2 0.4955 1.0000
r3 0.3477 0.8622 1.0000
r4 0.3012 0.7359 0.6677 1.0000
r5 0.2328 0.7431 0.7394 0.7701 1.0000
r6 0.0943 0.5671 0.5625 0.6166 0.7179 1.0000
/* compare with SAS proc mixed */
proc mixed data=temp;
class group visit2;
model dep = pre group visit / s;
repeated visit2 / subject=subj type=ar(1);
run;
( some output omitted )
Solution for Fixed Effects
Standard
Effect Estimate Error DF t Value Pr > |t|
pre 0.4284 0.1365 58 3.14 0.0027
group -4.0255 1.0267 58 -3.92 0.0002
visit -1.2189 0.1866 233 -6.53 <.0001
Intercept 5.1198 3.0428 58 1.68 0.0978
It not that there is anything particularly wrong with this analysis but it does require that we estimate many more parameters than in the ar1 model. It is actually quite easy to run out of degrees of freedom when using unstructured correlations.
Now, let's back up and reconsider the group by visit interaction. We will try a model with the interaction using the ar1 correlations.
generate gxv = group*visit
xtgee dep pre group visit gxv, fam(gaus) link(iden) i(subj) t(visit) corr(ar1)
GEE population-averaged model Number of obs = 287
Group and time vars: subj visit Number of groups = 53
Link: identity Obs per group: min = 2
Family: Gaussian avg = 5.4
Correlation: AR(1) max = 6
Wald chi2(4) = 64.83
Scale parameter: 25.81682 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
dep | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .4284649 .1377094 3.111 0.002 .1585595 .6983703
group | -3.55197 1.654127 -2.147 0.032 -6.794 -.3099395
visit | -1.057824 .3044115 -3.475 0.001 -1.654459 -.4611881
gxv | -.2040059 .3905217 -0.522 0.601 -.9694144 .5614026
_cons | 8.606923 3.147897 2.734 0.006 2.437158 14.77669
------------------------------------------------------------------------------
The group by visit interaction still is not significant even though this may be a better approach for testing it. So far we have been treating visit as a continuous variable. Is it possible that our analysis might change if we were to treat visit as a categorical variable, the way that the anova did? Let's try one last analysis using xi to create dummy variables on-the-fly.
xi: xtgee dep pre group i.visit, fam(gaus) link(iden) i(subj) corr(ar1)
GEE population-averaged model Number of obs = 287
Group and time vars: subj visit Number of groups = 53
Link: identity Obs per group: min = 2
Family: Gaussian avg = 5.4
Correlation: AR(1) max = 6
Wald chi2(7) = 66.85
Scale parameter: 25.67071 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
dep | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+--------------------------------------------------------------------
pre | .4264589 .1372194 3.108 0.002 .1575137 .6954041
group | -4.197096 1.050645 -3.995 0.000 -6.256323 -2.137869
Ivisit_2 | -.964717 .5556079 -1.736 0.083 -2.053689 .1242546
Ivisit_3 | -2.790063 .7474989 -3.733 0.000 -4.255134 -1.324992
Ivisit_4 | -3.730425 .8528421 -4.374 0.000 -5.401964 -2.058885
Ivisit_5 | -5.127078 .9147959 -5.605 0.000 -6.920045 -3.334111
Ivisit_6 | -5.84916 .9534054 -6.135 0.000 -7.7178 -3.98052
_cons | 7.896145 2.998003 2.634 0.008 2.020168 13.77212
------------------------------------------------------------------------------
test Ivisit_2 Ivisit_3 Ivisit_4 Ivisit_5 Ivisit_6
( 1) Ivisit_2 = 0.0
( 2) Ivisit_3 = 0.0
( 3) Ivisit_4 = 0.0
( 4) Ivisit_5 = 0.0
( 5) Ivisit_6 = 0.0
chi2( 5) = 40.56
Prob > chi2 = 0.0000The results are not very different from our previous analyses. In the final analysis, I think that I prefer the xtgee dep pre group visit, fam(gaus) link(iden) i(subj) t(visit) corr(ar1) analysis of all the analyses run so far.
Women with higher pretest scores on depression remained higher after treatment. Each point increase on the pretest was associated with about a .43 point increase on the predicted posttest depression score.
The results indicate that there was a significant effect for the estrogen patch when controlling for pretest depression and visit with estrogen path group being about 4 points lower on the depression scale.
There was also a significant visit effect when controlling for pretest depression and group membership.
Categorical Data Analysis Course
Phil Ender