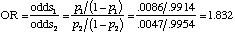
A table that cross classifies two variable is called a two-way contingency table. It is also known as a cross tabulation or crosstabs for short. If each of the two variables has two levels then the table is a 2x2. If there are three levels of one variable and 5 of the other, it would be a 3x5 table. We will start off by looking at a 2x2 table.
Observed Frequencies
The following table gives a representation of the observed frequencies of a 2x2 contingency table.
| column variable
row var | col 1 col 2 | Total
-----------+----------------------+--------
row 1 | n11 n12 | n1+
row 2 | n21 n22 | n2+
-----------+----------------------+--------
Total | n+1 n+2 | n
Here is what the observed frequencies look like for an example using myocardial infarction and the
use of aspirin.
| myocardial infarction
group | yes no | Total
-----------+----------------------+--------
placebo | 189 10845 | 11034
aspirin | 104 10933 | 11037
-----------+----------------------+--------
Total | 293 21778 | 22071
The values in the body of the table represent the joint distribution and the values around the
edges represent the marginal distributions.Observed Proportions
Here is a representation of the observed proportions which can also be treated as probabilities.
| column variable
row var | col 1 col 2 | Total
-----------+----------------------+--------
row 1 | p11 p12 | p1+
row 2 | p21 p22 | p2+
-----------+----------------------+--------
Total | p+1 p+2 | 1.0
The observed proportions for our example look like this:
| myocardial infarction
group | yes no | Total
-----------+----------------------+--------
placebo | .0086 .4914 | .4999
aspirin | .0047 .4954 | .5001
-----------+----------------------+--------
Total | .0133 .9867 | 1.0000
Relative RiskThe relative risk in a 2x2 table is the ratio of "success" probabilities for the two groups. For the MI example, it would look like this.
Odds Ratio
Before we can talk about odds ratios we need to define odds.
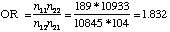
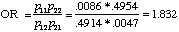
In this example, the odds of a myocardial infarction are 83% higher for the placebo group. If you take the reciprocal of the odds ratio the value is .546. Thus, the odds of myocardial infarction was about 45% lower for the aspirin group than for the placebo group.
Odds ratios are invariant when the orientation of the rows and columns reversed. The odds ratios are relatively invariant to changes in the marginal frequencies. For example, if you were to multiply each of the frequencies in the table by a constant, c, the odds ratio would remain unchanged.
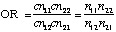
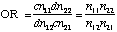
When p1 and p2 are both very small, the value of the odds ratio is close to that of the relative risk, In any case, the odds ratio can be obtained from the relative risk by the following formula.
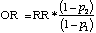
Conditional Probabilities
Conditional probabilities are the probabilities of an event given that some other event has occurred. In our MI example, the conditional probabilities for the groups are:
| myocardial infarction
group | yes no | Total
-----------+----------------------+--------
placebo | .0171 .9829 | 1.0000
aspirin | .0094 .9906 | 1.0000
-----------+----------------------+--------
Total | .0133 .9867 | 1.0000
Recall that,
| myocardial infarction
group | yes no | Total
-----------+----------------------+--------
placebo | .0086 .4914 | .4999
aspirin | .0047 .4954 | .5001
-----------+----------------------+--------
Total | .0133 .9867 | 1.0000
Thus, the conditional probability of a myocardial infarction for the placebo group is .0171, while
for the aspirin group in is .0094.Two variables are said to be independent when the conditional distributions of one are identical for each level of the other. In this example, the conditional distributions are not identical.
Expected Frequencies
Here are the expected frequencies for our example given independence of group and myocardial infarction.
| myocardial infarction
group | yes no | Total
-----------+-------------------------+--------
placebo | 146.480 10887.520 | 11034
aspirin | 146.520 10890.480 | 11037
-----------+-------------------------+--------
Total | 293 21778 | 22071
Note that the marginal frequencies are that same as in the table of the observed frequencies.
This is the case because the expected frequencies are obtained form the marginal distribution
of the observed frequencies. For example, the expected frequency of 146.480 is obtained as
follows:where ni+ is the frequency for the ith row, n+j is the frequency for the jth column, and n++ is the total frequency for the entire table.
This property is just a variation of the rule for the joint probability of independent events P(A & B) = P(A)*P(B).
Chi-Squared Statistic
In two-way contingency tables chi-squared is used to test the independence of the two marginal variables. The chi-squared test is often called a goodness-of-fit test but is perhaps better thought of as a badness-of-fit test, because a large value of chi-squared is indicative of a bad fit between the observed and expected frequencies.
There are two commonly computed chi-squared statistics; the Pearson chi-squared (χ2) and the likelihood ratio chi-squared (G2)
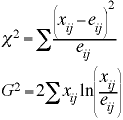
with degrees of freedom = (I-1)(J-1)
Stata Examples
use http://www.ats.ucla.edu/stat/data/hsbdemo, clear
tabulate ses prog, all
| type of program
ses | general academic vocation | Total
-----------+---------------------------------+----------
low | 16 19 12 | 47
middle | 20 44 31 | 95
high | 9 42 7 | 58
-----------+---------------------------------+----------
Total | 45 105 50 | 200
Pearson chi2(4) = 16.6044 Pr = 0.002
likelihood-ratio chi2(4) = 16.7830 Pr = 0.002
Cramer's V = 0.2037
gamma = 0.0109 ASE = 0.097
Kendall's tau-b = 0.0069 ASE = 0.062
tabulate ses prog, cell nofreq
| type of program
ses | general academic vocation | Total
-----------+---------------------------------+----------
low | 8.00 9.50 6.00 | 23.50
middle | 10.00 22.00 15.50 | 47.50
high | 4.50 21.00 3.50 | 29.00
-----------+---------------------------------+----------
Total | 22.50 52.50 25.00 | 100.00
tabulate ses prog, row nofreq
| type of program
ses | general academic vocation | Total
-----------+---------------------------------+----------
low | 34.04 40.43 25.53 | 100.00
middle | 21.05 46.32 32.63 | 100.00
high | 15.52 72.41 12.07 | 100.00
-----------+---------------------------------+----------
Total | 22.50 52.50 25.00 | 100.00
tabulate ses prog, expected
+--------------------+
| Key |
|--------------------|
| frequency |
| expected frequency |
+--------------------+
| type of program
ses | general academic vocation | Total
-----------+---------------------------------+----------
low | 16 19 12 | 47
| 10.6 24.7 11.8 | 47.0
-----------+---------------------------------+----------
middle | 20 44 31 | 95
| 21.4 49.9 23.8 | 95.0
-----------+---------------------------------+----------
high | 9 42 7 | 58
| 13.1 30.4 14.5 | 58.0
-----------+---------------------------------+----------
Total | 45 105 50 | 200
| 45.0 105.0 50.0 | 200.0
Pearson chi2(4) = 16.6044 Pr = 0.002
likelihood-ratio chi2(4) = 16.7830 Pr = 0.002
tabchi ses prog,raw pearson cont adjust noo noe /* findit tabchi */
raw residual
Pearson residual
contribution to chi-square
adjusted residual
----------------------------------------
| type of program
ses | general academic vocation
----------+-----------------------------
low | 5.425 -5.675 0.250
| 1.668 -1.142 0.073
| 2.783 1.305 0.005
| 2.167 -1.895 0.096
|
middle | -1.375 -5.875 7.250
| -0.297 -0.832 1.488
| 0.088 0.692 2.213
| -0.466 -1.666 2.371
|
high | -4.050 11.550 -7.500
| -1.121 2.093 -1.970
| 1.257 4.381 3.879
| -1.511 3.604 -2.699
----------------------------------------
Pearson chi2(4) = 16.6044 Pr = 0.002
likelihood-ratio chi2(4) = 16.7830 Pr = 0.002
A note about tetrachoric correlations
Tetrachoric correlations measure the association between two dichotomous variables by estimating the correlation between their associated latent variables.
The tabulate command includes an estimate of phi, a measure of association between dichotomous variables. Stata, in the 2x2 case, labels phi as "Cramer's V." The same coefficient can be obtained by computing a standard correlation correlation between the two variables.
use http://www.philender.com/courses/data/tetra, clear
tabulate hon sci, all
| sci
hon | 0 1 | Total
-----------+----------------------+----------
0 | 111 36 | 147
1 | 22 31 | 53
-----------+----------------------+----------
Total | 133 67 | 200
Pearson chi2(1) = 20.2150 Pr = 0.000
likelihood-ratio chi2(1) = 19.4693 Pr = 0.000
Cramer's V = 0.3179
gamma = 0.6258 ASE = 0.103
Kendall's tau-b = 0.3179 ASE = 0.072
corr hon sci
(obs=200)
| hon sci
-------------+------------------
hon | 1.0000
sci | 0.3179 1.0000
polychoric hon sci /* findit polychoric */
Variables : hon sci
Type : polychoric
Rho = .504248
S.e. = .09873079
Goodness of fit tests:
Pearson G2 = .00911031, Prob( >chi2(0)) = .
LR X2 = .00910615, Prob( >chi2(0)) = .
polychoric female schtyp ses hon sci
matrix list r(R)
symmetric r(R)[5,5]
female schtyp ses hon sci
female 1
schtyp -.02893308 1
ses -.26297321 -.44527627 1
hon .23643947 .03044205 .07352325 1
sci -.25634248 -.12494757 .2666472 .504248 1
Categorical Data Analysis Course
Phil Ender